Tiering Service Deep Dive

Background
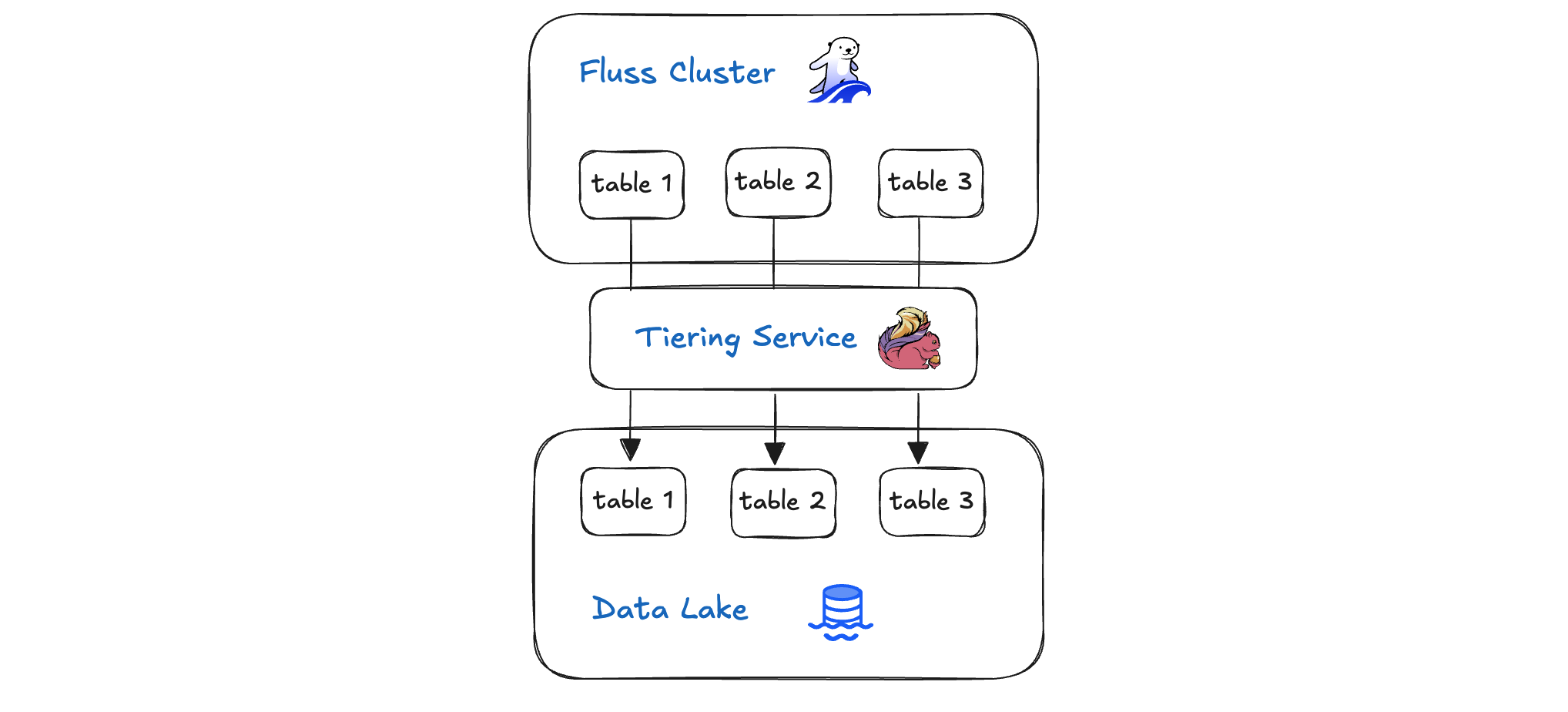
At the core of Fluss’s Lakehouse architecture sits the Tiering Service: a smart, policy-driven data pipeline that seamlessly bridges your real-time Fluss cluster and your cost-efficient lakehouse storage. It continuously ingests fresh events from the fluss cluster, automatically migrating older or less-frequently accessed data into colder storage tiers without interrupting ongoing queries. By balancing hot, warm, and cold storage according to configurable rules, the Tiering Service ensures that recent data remains instantly queryable while historical records are archived economically.
In this blog post we will take a deep dive and explore how Fluss’s Tiering Service orchestrates data movement, preserves consistency, and empowers scalable, high-performance analytics at optimized costs.
Flink Tiering Service
Fluss tiering service is an Apache Flink job, which keeps moving data from fluss cluster to data lake.
The execution plan is quite straight forward. It has a three operators: a source, a committer and an empty sink writer.
Source: TieringSource -> TieringCommitter -> Sink: Writer
- TieringSource: Reads records from the Fluss tiering table and writes them to the data lake.
- TieringCommitter: Commits each sync batch by advancing offsets in both the lakehouse and the Fluss cluster.
- No-Op Sink: A dummy sink that performs no action.
In the sections that follow, we’ll dive into the TieringSource and TieringCommitter to see exactly how they orchestrate seamless data movement between real-time and historical storage.
TieringSource
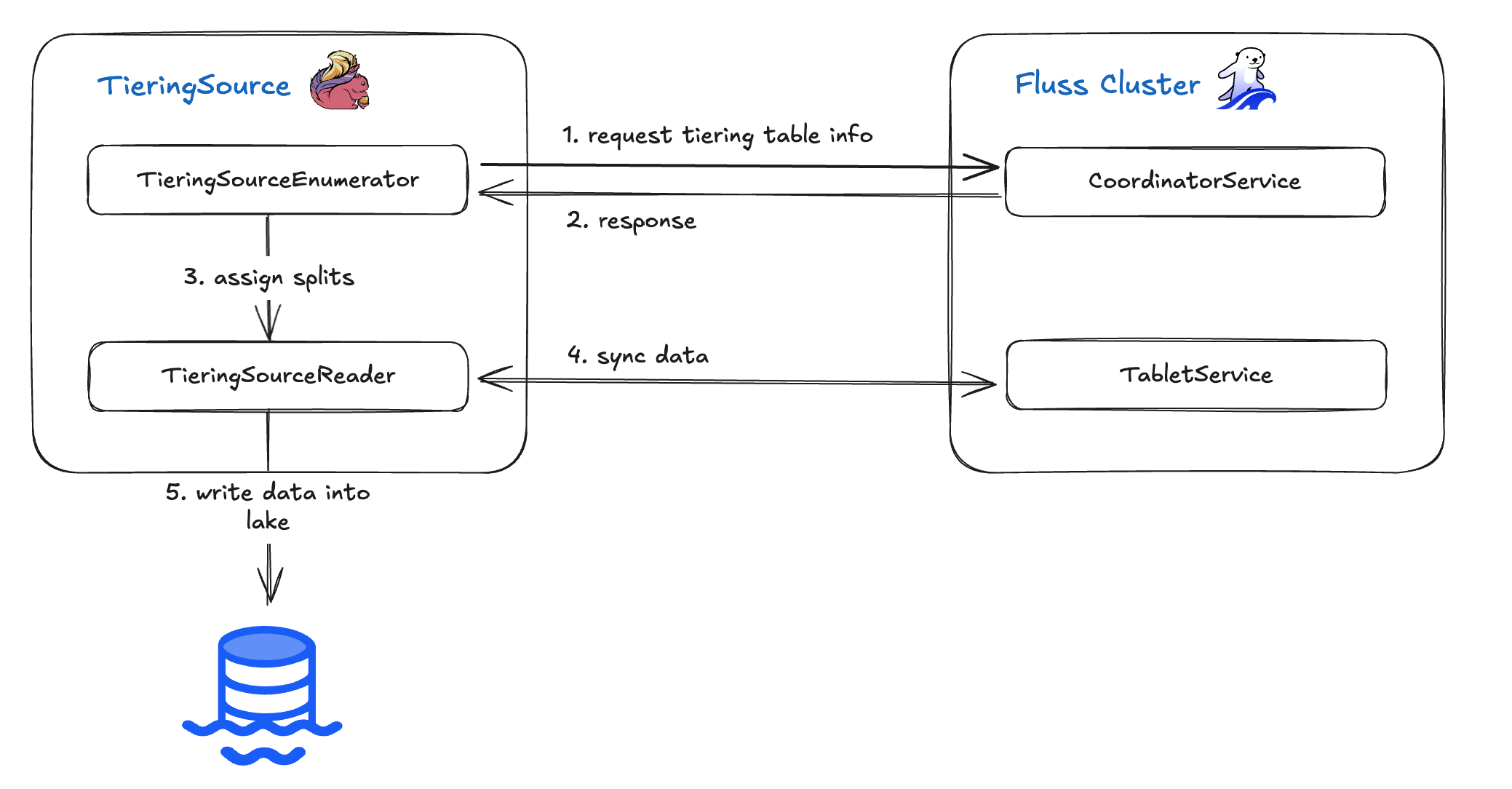
The TieringSource operator reads records from the Fluss tiering table and writes them into your data lake. Built on Flink’s Source V2 API (FLIP-27), it breaks down into two core components: the TieringSourceEnumerator and the TieringSourceReader. The high-level workflow is as follows:
- The Enumerator queries the CoordinatorService for current tiering table metadata.
- Once it receives the table information, the Enumerator generates
“splits”(data partitions) and assigns them to the Reader. - The Reader fetches the actual data for each split.
- Finally the Reader writes those records into the data lake.
In the following sections, we’ll explore how the TieringSourceEnumerator and TieringSourceReader work under the hood to deliver reliable, scalable ingestion from Fluss into your lakehouse.
TieringSourceEnumerator
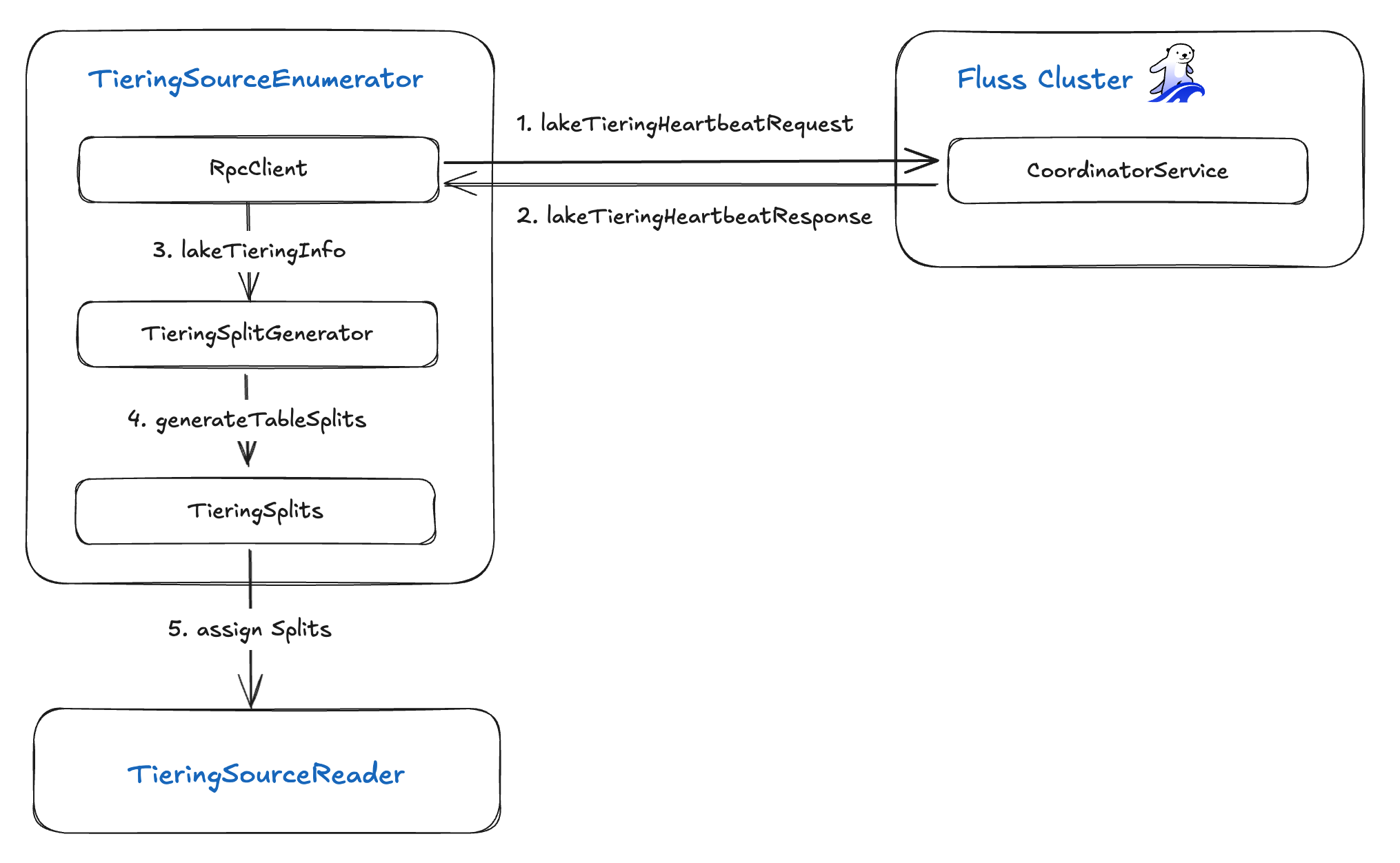
The TieringSourceEnumerator orchestrates split creation and assignment in five key steps:
- Heartbeat Request: Uses an RPC client to send a
lakeTieringHeartbeatRequestto the Fluss server. - Heartbeat Response: Receives a
lakeTieringHeartbeatResponsethat contains the tiering table metadata and sync statuses forcompleted,failed, andin-progresstables. - Lake Tiering Info: Forwards the returned
lakeTieringInfoto theTieringSplitGenerator. - Split Generation: The
TieringSplitGeneratorproduces a set ofTieringSplits, each representing a data partition to process. - Split Assignment: Assigns those
TieringSplitstoTieringSourceReaderinstances for downstream ingestion into the data lake.
RpcClient
The RpcClient inside the TieringSourceEnumerator handles all RPC communication with the Fluss CoordinatorService. Its responsibilities include:
- Sending Heartbeats: It constructs and sends a
LakeTieringHeartbeatRequest, which carries three lists of tables—tiering_tables(in-progress),finished_tables, andfailed_tables—along with an optionalrequest_tableflag to request new tiering work. - Receiving Responses: It awaits a
LakeTieringHeartbeatResponsethat contains:coordinator_epoch: the current epoch of the coordinator.tiering_table(optional): aPbLakeTieringTableInfomessage (withtable_id,table_path, andtiering_epoch) describing the next table to tier.tiering_table_resp,finished_table_resp, andfailed_table_resp: lists of heartbeat responses reflecting the status of each table.
- Forwarding Metadata: It parses the returned
PbLakeTieringTableInfoand the sync-status responses, then forwards the assembledlakeTieringInfoto theTieringSplitGeneratorfor split creation.
TieringSplitGenerator
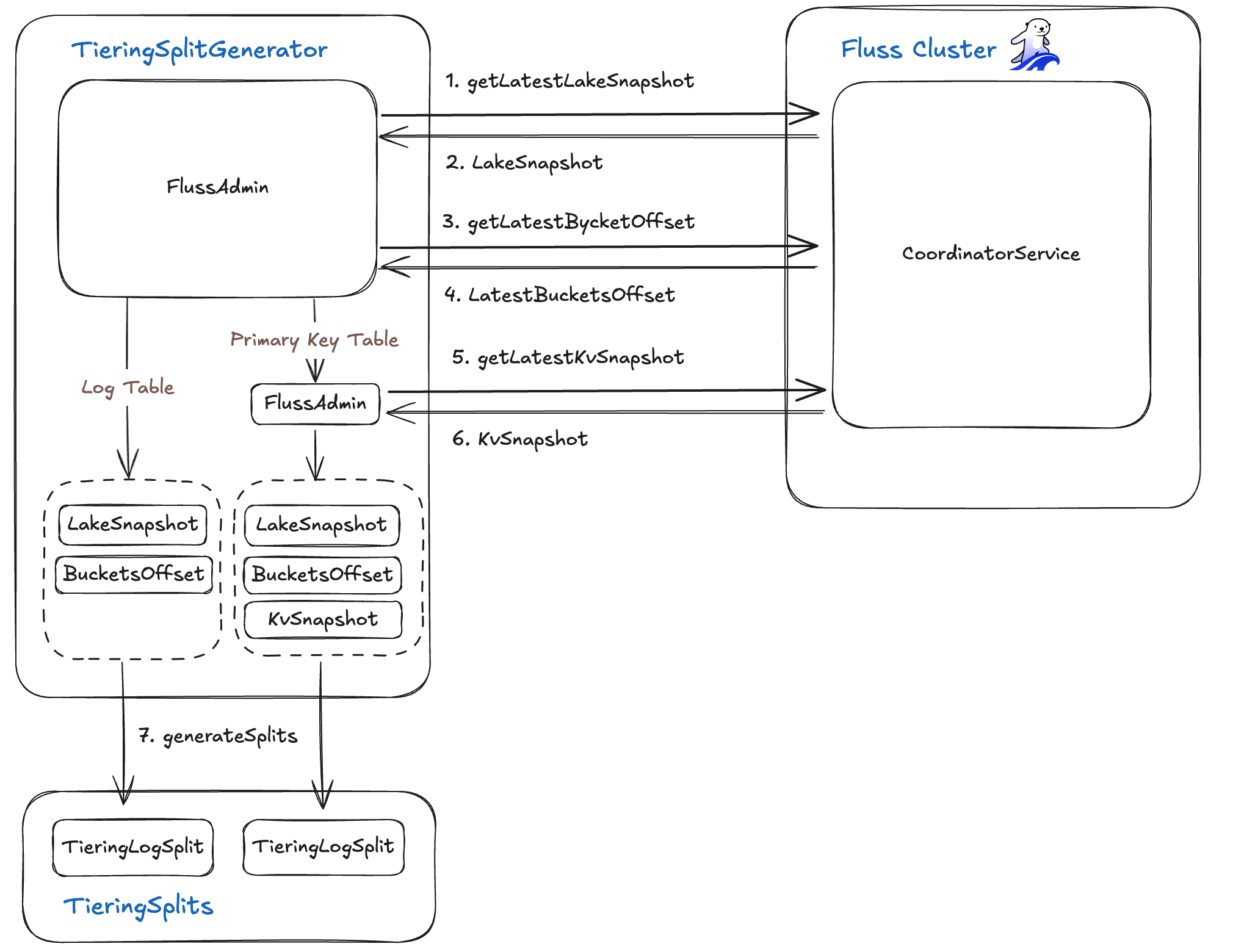
The TieringSplitGenerator is an important component that orchestrates efficient data synchronization between your real-time Fluss cluster and your lakehouse.
It precisely calculates the data "delta", i.e what's new or changed in Fluss but not yet committed to the lake and then generates TieringSplit tasks for each segment requiring synchronization.
To achieve this, the TieringSplitGenerator leverages the FlussAdminClient to fetch three essential pieces of metadata:
Lake Snapshot
The generator first invokes the lake metadata API to retrieve a LakeSnapshot object. This snapshot provides a complete picture of the current state of your data in the lakehouse, including:
snapshotId:The identifier for the latest committed snapshot in your data lake.tableBucketsOffset:A map that details the log offset in the lakehouse for eachTableBucket.
Current Bucket Offsets
Next, the TieringSplitGenerator queries the Fluss server to determine the current log end offset for each bucket. This effectively captures the high-water mark of incoming data streams in real time within your Fluss cluster.
KV Snapshots (for primary-keyed tables)
For tables that utilize primary keys, the generator also retrieves a KvSnapshots record. This record contains vital information for maintaining consistency with key-value stores:
tableIdand an optionalpartitionId.snapshotIds:The latest snapshot ID specific to each bucket.logOffsets:The exact log position from which to resume reading after that snapshot, ensuring seamless data ingestion.
With the LakeSnapshot, the live bucket offsets from the Fluss cluster, and (where applicable) the KvSnapshots, the TieringSplitGenerator performs its core function: it computes which log segments are present in Fluss but have not yet been committed to the lakehouse.
Finally, for each identified segment, it produces a distinct TieringSplit. Each TieringSplit precisely defines the specific bucket and the exact offset range that needs to be ingested. This meticulous process ensures incremental, highly efficient synchronization, seamlessly bridging your real-time operational data with your historical, cost-optimized storage.
TieringSplit
The TieringSplit abstraction defines exactly which slice of a table bucket needs to be synchronized. It captures three common fields:
- tablePath: the full path to the target table.
- tableBucket: the specific bucket (shard) within that table.
- partitionName (optional): the partition key, if the table is partitioned.
There are two concrete split types:
- TieringLogSplit (for append-only “log” tables)
- startingOffset: the last committed log offset in the lake.
- stoppingOffset: the current end offset in the live Fluss bucket.
- This split defines a contiguous range of new log records to ingest.
- TieringSnapshotSplit (for primary-keyed tables)
- snapshotId: the identifier of the latest snapshot in Fluss.
- logOffsetOfSnapshot: the log offset at which that snapshot was taken.
- This split lets the TieringSourceReader replay all CDC (change-data-capture) events since the snapshot, ensuring up-to-date state.
By breaking each table into these well-defined splits, the Tiering Service can incrementally, reliably, and in parallel sync exactly the data that’s missing from your data lake.
TieringSourceReader
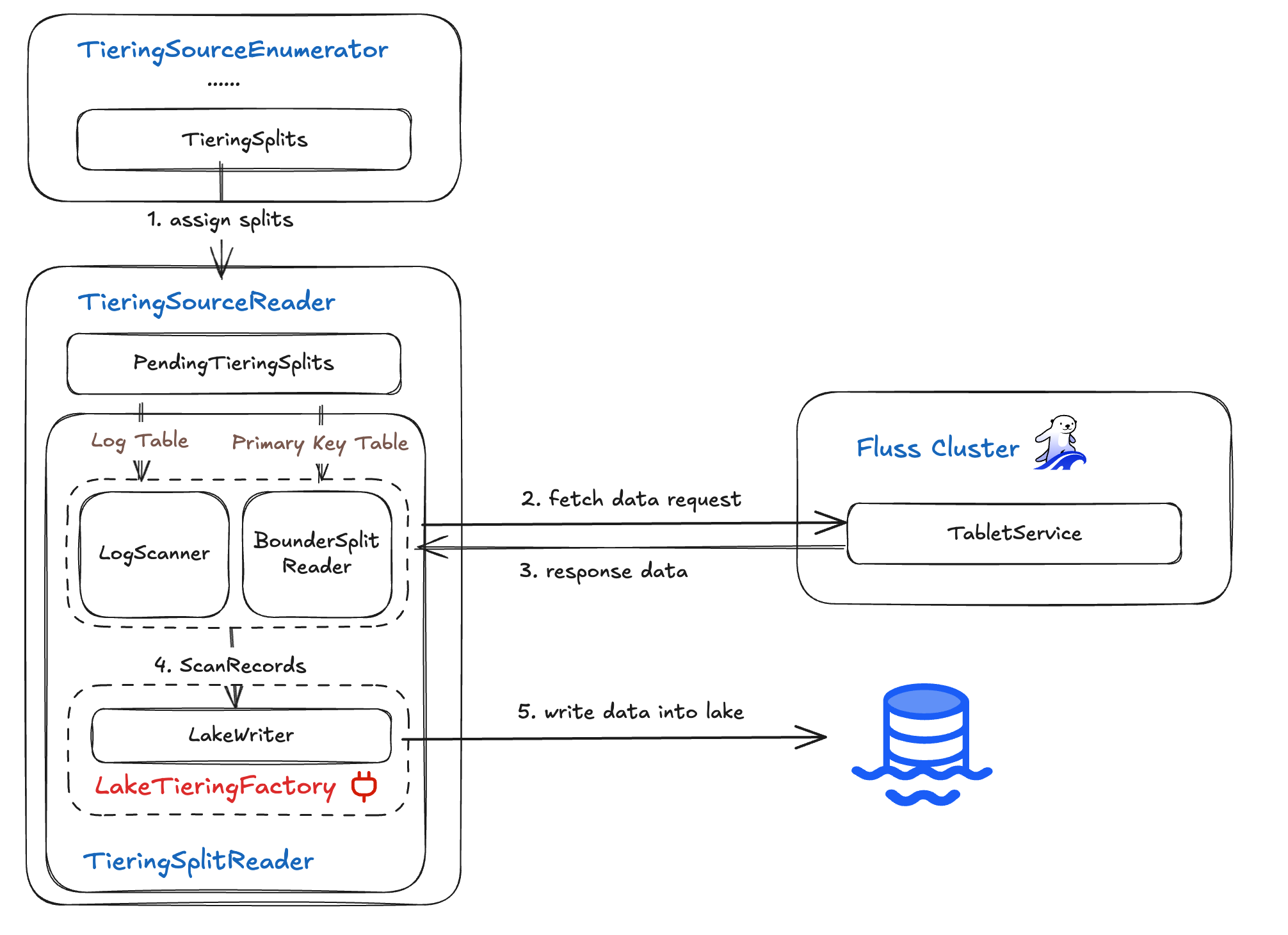
The TieringSourceReader pulls assigned splits from the enumerator, uses a TieringSplitReader to fetch the corresponding records from the Fluss server, and then writes them into the data lake. Its workflow breaks down as follows:
- Split Selection: The reader picks an assigned
TieringSplitfrom its queue. - Reader Dispatch: Depending on the split type, it instantiates either:
- LogScanner for
TieringLogSplit(append-only tables) - BoundedSplitReader for
TieringSnapshotSplit(primary-keyed tables)
- LogScanner for
- Data Fetch: The chosen reader fetches the records defined by the split’s offset or snapshot boundaries from the Fluss server.
- Lake Writing" Retrieved records are handed off to the lake writer, which persists them into the data lake.
By cleanly separating split assignment, reader selection, data fetching, and lake writing, the TieringSourceReader ensures scalable, parallel ingestion of streaming and snapshot data into your lakehouse.
LakeWriter & LakeTieringFactory
The LakeWriter is responsible for persisting Fluss records into your data lake, and it’s instantiated via a pluggable LakeTieringFactory. This interface defines how Fluss interacts with various lake formats (e.g., Paimon, Iceberg):
public interface LakeTieringFactory {
LakeWriter<WriteResult> createLakeWriter(WriterInitContext writerInitContext);
SimpleVersionedSerializer<WriteResult> getWriteResultSerializer();
LakeCommitter<WriteResult, CommitableT> createLakeCommitter(
CommitterInitContext committerInitContext);
SimpleVersionedSerializer<CommitableT> getCommitableSerializer();
}
- createLakeWriter(WriterInitContext): builds a
LakeWriterto convert Fluss rows into the target table format. - getWriteResultSerializer(): supplies a serializer for the writer’s output.
- createLakeCommitter(CommitterInitContext): constructs a
LakeCommitterto finalize and atomically commit data files. - getCommitableSerializer(): provides a serializer for committable tokens.```
By default, Fluss includes a Paimon-backed tiering factory; Iceberg support is coming soon. Once the TieringSourceReader writes a batch of records through the LakeWriter, it emits the resulting write metadata downstream to the TieringCommitOperator, which then commits those changes both in the lakehouse and back to the Fluss cluster.
Stateless
The TieringSourceReader is designed to be completely stateless—it does not checkpoint or store any TieringSplit information itself. Instead, every checkpoint simply returns an empty list, leaving all split-tracking to the TieringSourceEnumerator:
@Override
public List<TieringSplit> snapshotState(long checkpointId) {
// Stateless: no splits are held in reader state
return Collections.emptyList();
}
By delegating split assignment entirely to the Enumerator, the reader remains lightweight and easily scalable, always fetching its next work unit afresh from the coordinator.
TieringCommitter
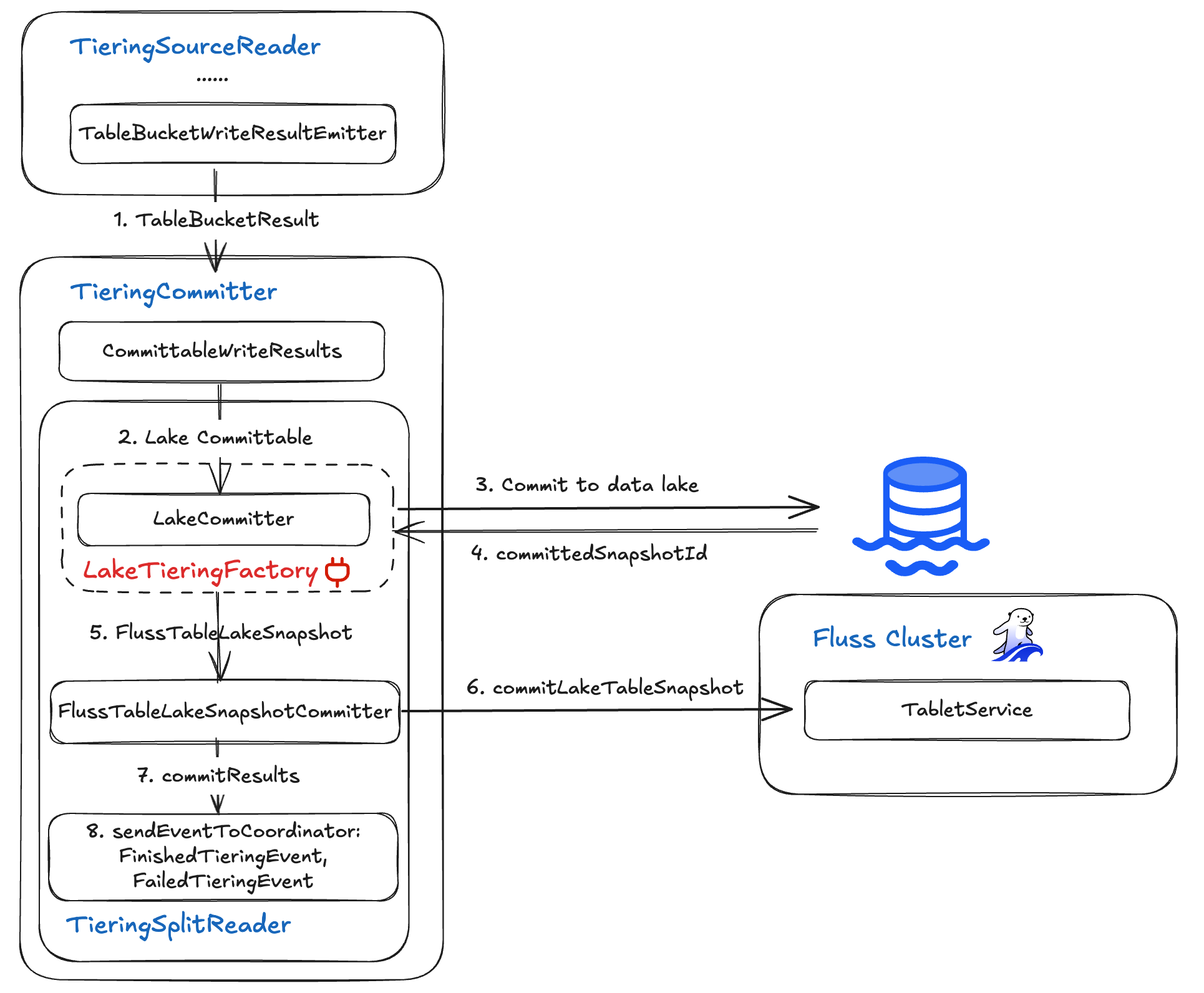
The TieringCommitter operator wraps up each sync cycle by taking the WriteResult outputs from the TieringSourceReader and committing them in two phases:
first to the data lake, then back to Fluss, before emitting status events to the Flink coordinator. It leverages two components:
- LakeCommitter: Provided by the pluggable
LakeTieringFactory, this component atomically commits the written files into the lakehouse and returns the new snapshot ID. - FlussTableLakeSnapshotCommitter: Using that snapshot ID, it updates the Fluss cluster’s tiering table status so that the Fluss server and lakehouse remain in sync.
The end-to-end flow is:
- Collect Write Results from the TieringSourceReader for the current checkpoint.
- Lake Commit via the
LakeCommitter, which finalizes files and advances the lake snapshot. - Fluss Update using the
FlussTableLakeSnapshotCommitter, acknowledging success or failure back to the Fluss CoordinatorService. - Event Emission of either
FinishedTieringEvent(on success or completion) orFailedTieringEvent(on errors) to the FlinkOperatorCoordinator.
This TieringCommitter operator ensures exactly-once consistent synchronization between your real-time Fluss cluster and your analytical lakehouse.
Conclusion
In this deep dive, we thoroughly explored every facet of Fluss's Tiering Service. We began by dissecting the TieringSource, understanding the critical roles of its Enumerator, RpcClient, and SplitGenerator. From there, we examined the various split types and the efficiency of the stateless TieringSourceReader.
Our journey then led us to the flexible, pluggable integration of the LakeWriter and LakeCommitter. Finally, we saw how the TieringCommitter, with its LakeCommitter and FlussTableLakeSnapshotCommitter, orchestrates atomic, exactly-once commits across both your data lake and Fluss cluster.
Together, these components form a robust pipeline. This pipeline reliably synchronizes real-time streams with historical snapshots, ensuring seamless, scalable consistency between your live workloads and analytical storage.