Overview
Below, we provide an overview of the key components of a Fluss cluster, detailing their functionalities and implementations. Additionally, we will introduce the various deployment methods available for Fluss.
Overview and Reference Architecture
The figure below shows the building blocks of Fluss clusters:
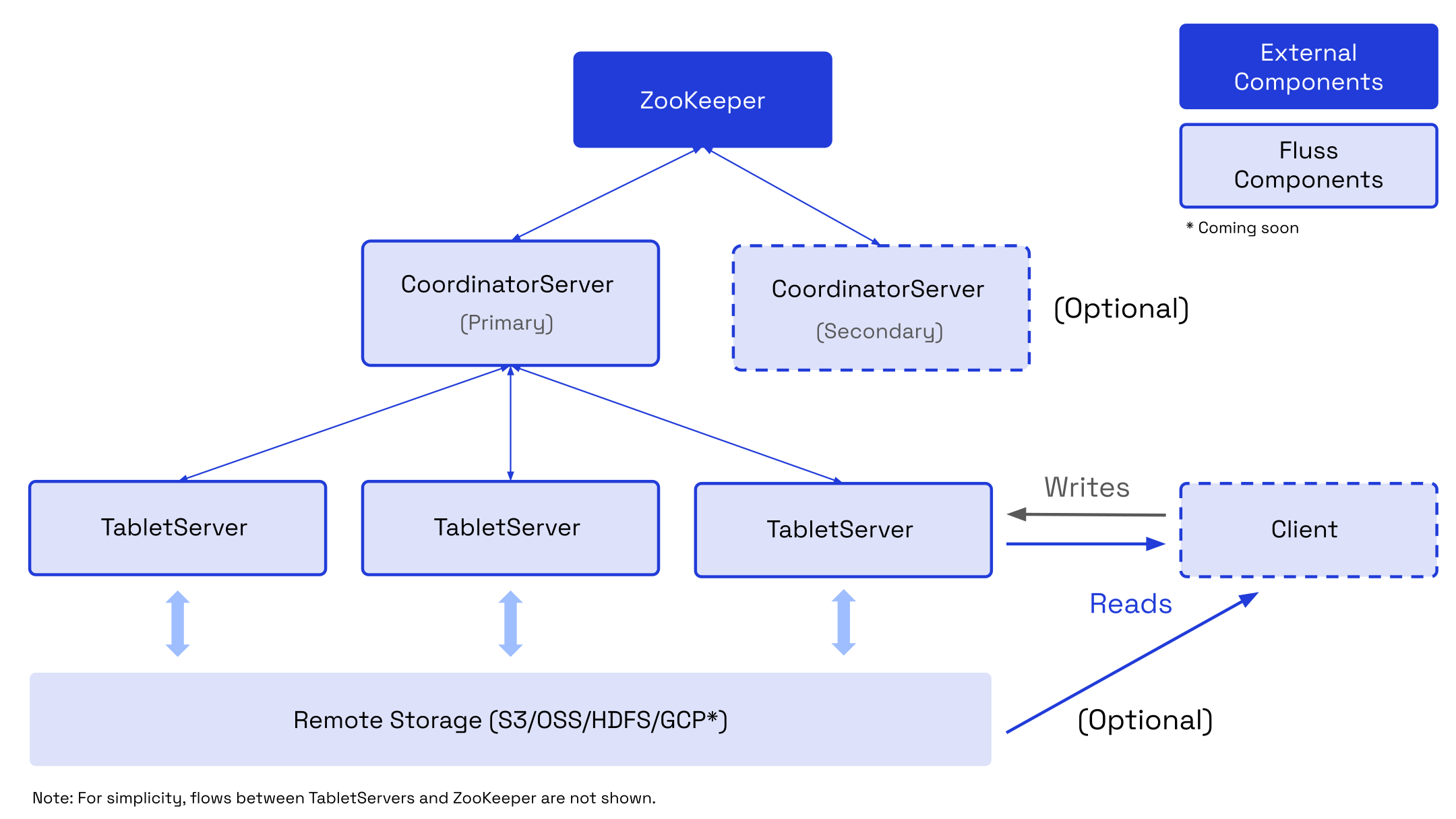
When deploying Fluss, there are often multiple options available for each building block. We have listed them in the table below the figure.
| Component | Purpose | Implementations |
|---|---|---|
| Fluss Client | The Fluss Client is the entry point for users to interact with Fluss Cluster. It is responsible for managing Fluss Cluster like:
| |
| CoordinatorServer | CoordinatorServer is the name of the central work coordination component of Fluss. The coordinator server is responsible to:
| |
| TabletServer | TabletServers are the actual node to manage and store data. | |
| External Components | ||
| ZooKeeper | warning Zookeeper will be removed to simplify deployment in the near future. For more details, please checkout Roadmap. Fluss leverages ZooKeeper for distributed coordination between all running CoordinatorServer instances and for metadata management. | |
| Remote Storage (optional) | Fluss uses file systems as remote storage to store snapshots for Primary-Key Table and store tiered log segments for Log Table. | |
| Lakehouse Storage (optional) | Fluss's DataLake Tiering Service will continuously compact Fluss's Arrow files into Parquet/ORC files in open lake format. The data in Lakehouse storage can be read both by Fluss's client in a Union Read manner and accessed directly by query engines such as Flink, Spark, StarRocks, Trino. | |
| Metrics Storage (optional) | CoordinatorServer/TabletServer report internal metrics and Fluss client (e.g., connector in Flink jobs) can report additional, client specific metrics as well. | |
How to deploy Fluss
Fluss can be deployed in three different ways:
NOTE:
- Local Cluster is for testing purpose only.