Overview
With tiered storage, Fluss allows you to scale compute and storage resources independently, provides better client isolation, and allows faster maintenance.
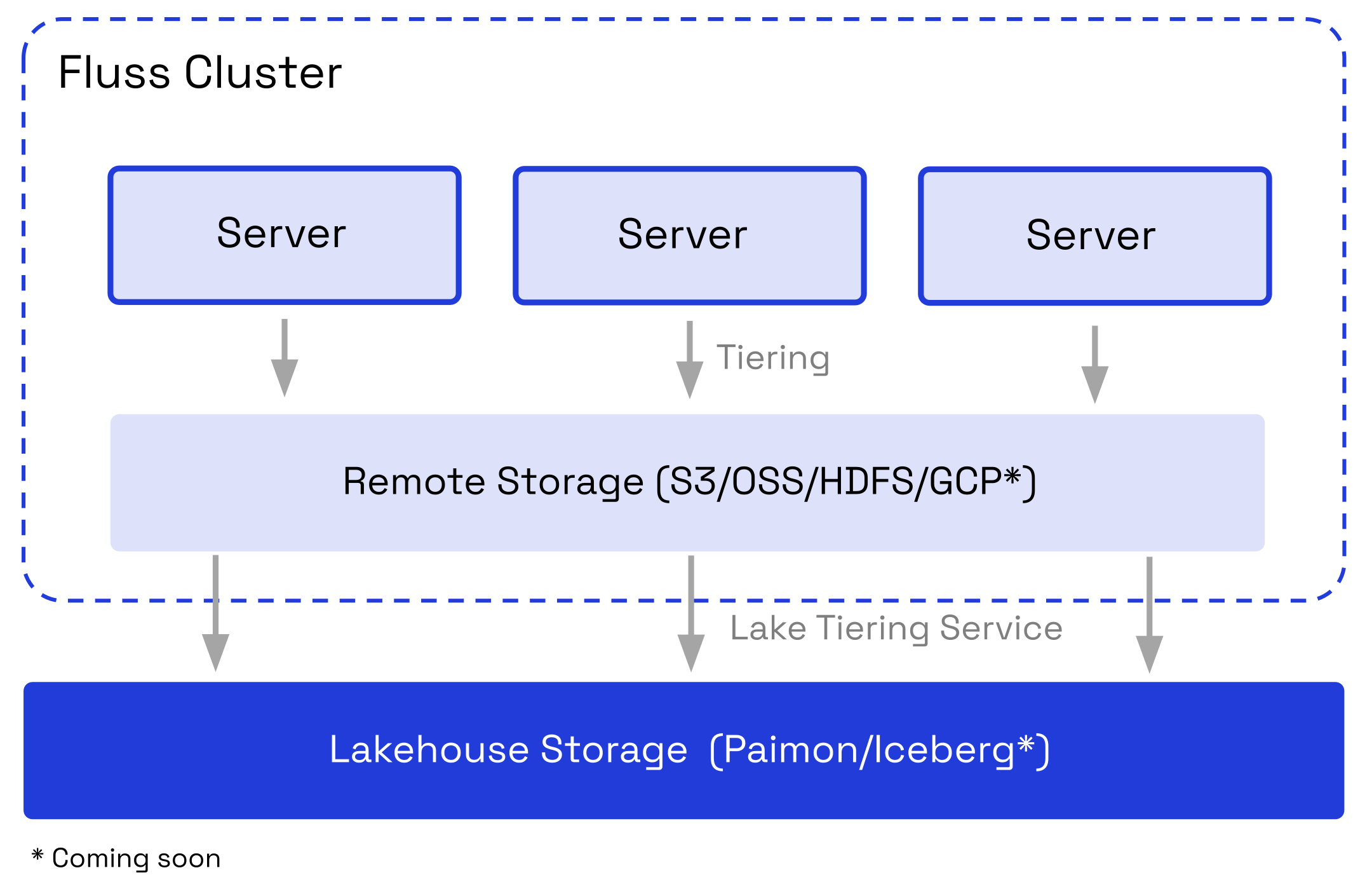
Fluss organizes data into different storage layers based on its access patterns, performance requirements, and cost considerations.
Fluss ensures the recent data is stored in local for higher write/read performance and the historical data is stored in remote storage for lower cost.
What's more, since the native format of Fluss's data is optimized for real-time write/read which is inevitable unfriendly to batch analytics, Fluss also introduces a lakehouse storage which stores the data in the well-known open data lake format for better analytics performance. Currently, only Paimon is supported, but more kinds of data lake support are on the way. Keep eyes on us!
The overall tiered storage architecture is shown in the following diagram: