AgenticPipeline
Agentic Pipeline Architecture Diagram
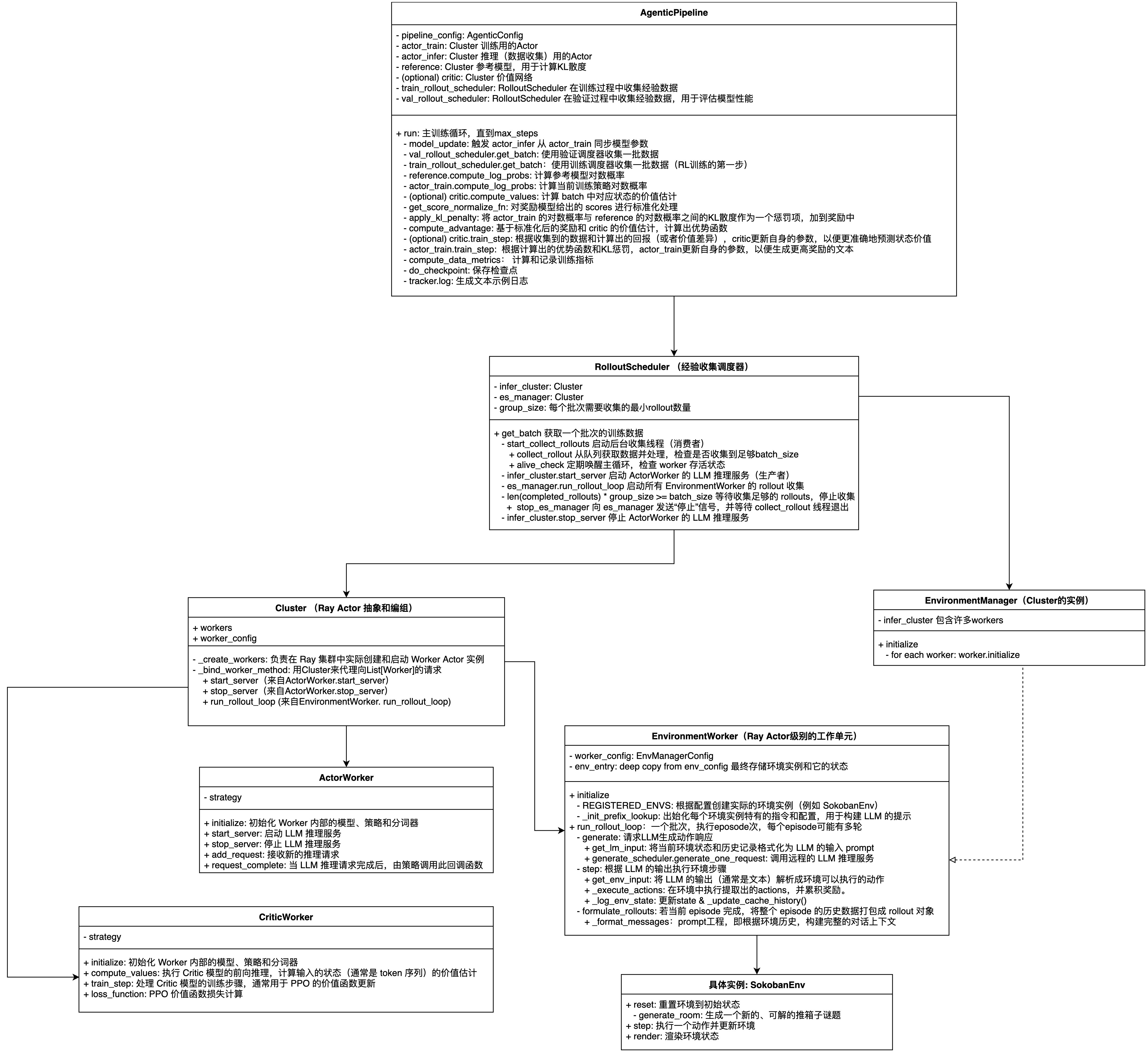
AgenticPipeline
AgenticPipeline is a core component in the ROLL framework, used for reinforcement learning training of agents. AgenticPipeline inherits from BasePipeline and implements the PPO (Proximal Policy Optimization) algorithm based on the Actor-Critic architecture, providing a complete distributed training pipeline for large language model agent training.
Main Attributes
Core Configuration
- pipeline_config: The core configuration object of the AgenticPipeline class, of type AgenticConfig, containing all configuration parameters for the entire reinforcement learning training pipeline.
Actor-Critic Architecture Clusters
- actor_train: The policy network training cluster in AgenticPipeline, responsible for executing the core training logic of the PPO algorithm.
- actor_infer: The policy network inference cluster in AgenticPipeline, responsible for interacting with the environment to generate training data.
- reference: The reference model cluster in AgenticPipeline, serving as a baseline model in the policy optimization process for calculating KL divergence.
- critic (optional): Estimates the state value function (only used in GAE mode)
Environment Interaction Scheduler
- train_rollout_scheduler: Collects experience data during training, where infer_cluster=actor_infer
- val_rollout_scheduler: Collects experience data during validation to evaluate model performance, where infer_cluster=actor_infer
Controllers and Auxiliary Tools
- kl_ctrl: Adaptively adjusts the KL penalty coefficient to prevent the policy update from deviating too far from the reference policy
- tokenizer: Handles text encoding and decoding
- running: Calculates and maintains runtime statistics
Core Process
def run():
Initialize TPS timer
for global_step in range(max_steps):
# 1. Model state management
Update model parameters (actor_train -> actor_infer)
# 2. Evaluation phase (executed every eval_steps)
if global_step % eval_steps == 0:
batch = Validation environment rollout(val_batch_size)
Calculate evaluation metrics (score mean/max/min)
Save render results (optional)
# 3. Training data collection
batch = Training environment rollout(rollout_batch_size)
# 4. Calculate key probabilities and values
ref_log_probs = Reference model.calculate log probabilities(batch)
old_log_probs = Actor_train model.calculate log probabilities(batch)
if using GAE estimator:
values = Critic model.calculate value function(batch)
# 5. Reward processing and advantage calculation
Normalize reward scores by group
Apply KL penalty
Calculate advantage function (GAE or other methods)
# 6. Model training
if using GAE estimator:
Critic model.training step(batch)
if global_step > critic_warmup:
Actor model.training step(batch)
# 7. Record and save
Record training metrics
Save checkpoints
Print sample logs (every logging_steps)
model_update
Synchronize training model parameters to the inference model to ensure that the inference model used for generating rollout data uses the latest training parameters. In the PPO algorithm, the training model actor_train is responsible for parameter updates and gradient calculations, while the inference model actor_infer is responsible for generating rollout data. To ensure training consistency, the inference model needs to periodically synchronize the latest training data, so that the generated rollout data can reflect the true performance of the current policy.
# Initialize phase to set synchronization pairs
self.set_model_update_pair(
src_cluster=self.actor_train,
tgt_cluster=self.actor_infer,
frequency=self.pipeline_config.actor_train.model_update_frequency,)
# Execute synchronization in training loop
model_update_metrics: Dict = self.model_update(global_step)
metrics.update(model_update_metrics)
train_rollout
Generate rollout data for training, i.e., let the agent interact with the environment to produce experience data (state, action, reward sequences).
self.train_rollout_scheduler.get_batch(batch, self.pipeline_config.rollout_batch_size)
val_rollout
Use the validation set rollout scheduler to generate a batch of validation data. Validate every eval_steps steps.
self.val_rollout_scheduler.get_batch(batch,self.pipeline_config.val_batch_size)
cal_ref_log_probs
reference.compute_log_probs calculates the log probabilities of the reference model for the current batch data. Used for subsequent KL divergence penalty calculation to prevent the training policy from deviating too far from the initial policy.
cal_old_log_probs_values
Calculate the log probabilities (old policy probabilities) and value function estimates of the current training model for rollout data, which is a key step in the PPO algorithm for calculating the importance sampling ratio. actor_train.compute_log_probs uses the current training model to calculate the log probabilities of rollout data. critic.compute_values, if using GAE, also calculates the state value function.
self.actor_train.compute_log_probs(batch, blocking=False)
if self.pipeline_config.adv_estimator == "gae":
self.critic.compute_values(batch, blocking=False)
adv
Implements reward processing and advantage calculation, which is a core step in the PPO algorithm, responsible for converting environment rewards into training signals.
get_score_normalize_fnstandardizes the scores given by the reward modelapply_kl_penaltyadds the KL divergence between the log probabilities of actor_train and reference as a penalty term to the reward.compute_advantagecalculates the advantage function based on the normalized rewards and the critic's value estimates.
critic.train_step (optional)
Based on the collected data and calculated returns (or value differences), the critic updates its parameters to more accurately predict state values.
if self.pipeline_config.adv_estimator == "gae":
self.critic.train_step(batch, blocking=False)
actor_train.train_step
actor_train.train_step updates its parameters based on the calculated advantage function and KL penalty, in order to generate text with higher rewards.
compute_data_metrics
Calculate and statistics key metrics of training data, providing comprehensive data analysis for monitoring the training process.
do_checkpoint
Save checkpoints
tracker.log
Generate text sample logs