实验数据分析与查看
实验数据追踪
pipeline对应的config文件中,提供了两种数据追踪方式
- TensorBoard
- Weights & Biases (wandb)
# wandb (Weights & Biases) 提供了更高级的云端实验管理和协作功能。
#track_with: wandb
#tracker_kwargs:
# api_key:
# project: roll-agentic
# name: ${exp_name}_frozen_lake
# notes: "agentic_pipeline"
# tags:
# - agentic
# - roll
# - baseline
track_with: tensorboard
tracker_kwargs:
# log_dir 是 TensorBoard 日志文件的根目录。每次实验运行会在该目录下创建以时间戳命名的子目录。
log_dir: /data/oss_bucket_0/yali/llm/tensorboard/roll_exp/agentic_sokoban
实验数据可视化
下文以TensorBoard为例,介绍如何可视化查看实验数据
- 确保TensorBoard已安装
pip install tensorboard
- 启动TensorBoard。pipeline运行结束后,在log_dir目录下(例如 /data/oss_bucket_0/yali/llm/tensorboard/roll_exp/agentic_sokoban),可以找到以日期时间命名的各个实验运行目录。通过以下命令启动tensorboard,它将扫描该日期时间目录下的运行日志:
tensorboard --logdir /data/oss_bucket_0/yali/llm/tensorboard/roll_exp/agentic_sokoban/{latest_date}
在终端中,会看到如下提示

在浏览器中打开localhost:6006,即可查看TensorBoard界面。如果在远程机器上使用,需要正确配置端口映射。
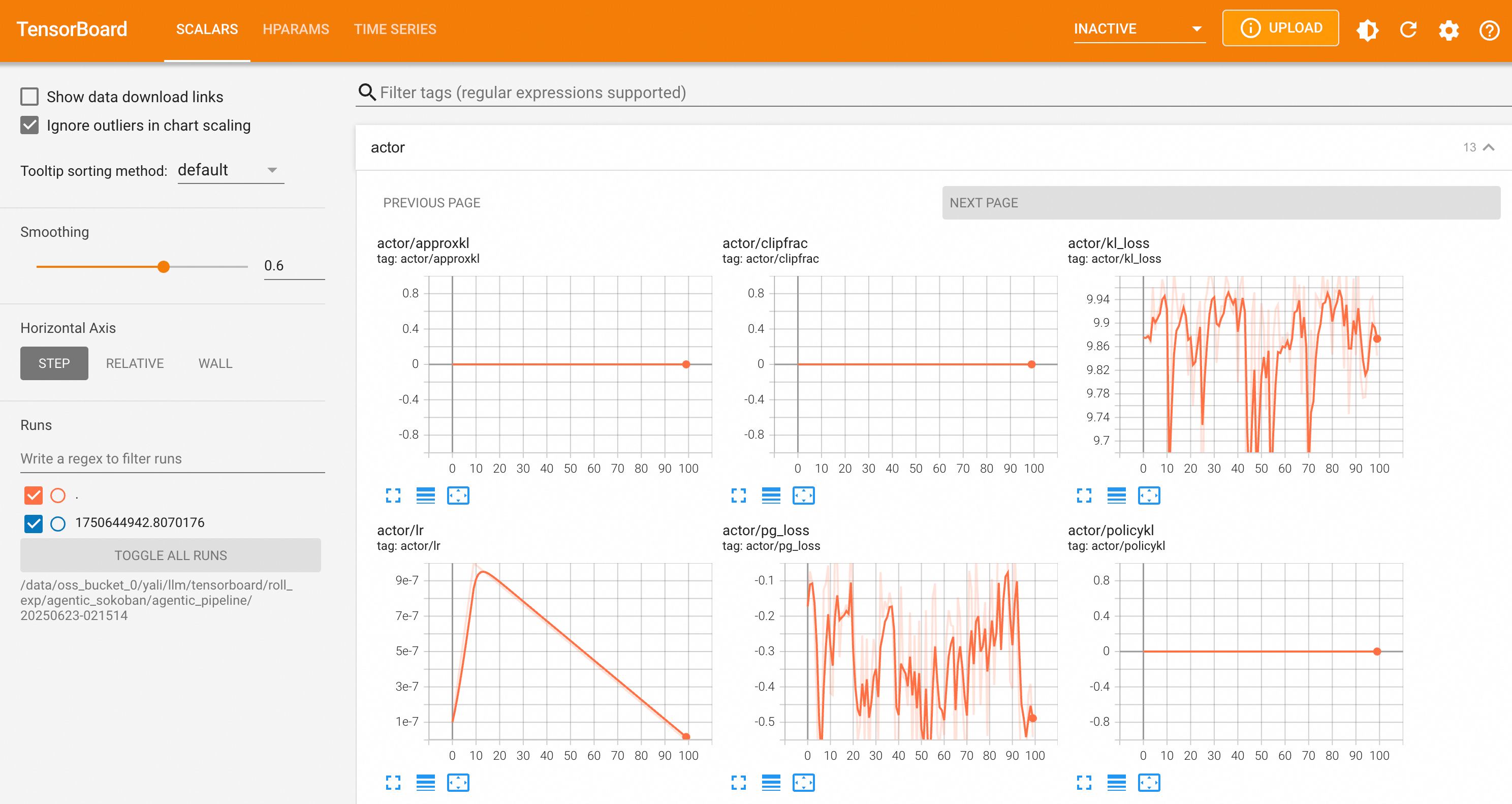
算法效果指标
验证阶段
- val/score/mean: 验证阶段,每个 episode 的平均分数。反映模型在未见过环境上的平均表现。
- val/score/max / val/score/min: 验证阶段,每个 episode 的最高分数 / 最低分数。
价值相关
- critic/lr: 价值函数(Critic)的学习率。学习率是优化器更新模型参数的步长。
- critic/loss: 价值网络预测值与真实回报之间的损失。
- critic/value: 数据收集或训练开始时,旧策略的价值网络对批次中状态的预测值均值。这些值通常在计算优势函数时作为基准。
- critic/vpred: 当前正在优化中的价值网络对批次中状态的预测值均值。该值会随着训练迭代而更新。
- critic/clipfrac: 价值函数是否使用了裁剪(value_clip)以及裁剪生效的比例。
- critic/error: 价值网络预测值与真实回报之间的均方误差。
奖励相关
- critic/score/mean: 环境原始奖励的均值。
- critic/score/max / critic/score/min: 环境原始奖励的最大值 / 最小值。
- critic/rewards/mean: 经过归一化/裁剪的奖励均值。
- critic/rewards/max / critic/rewards/min: 经过归一化/裁剪的奖励的最大值 / 最小值。
- critic/advantages/mean: 优势(Advantages)的均值。反映了在给定状态下采取某个行动相对于平均水平能带来多少额外奖励。
- critic/advantages/max / critic/advantages/min: 优势(Advantages)的最大值 / 最小值。
- critic/returns/mean: 回报(Returns)的均值。期望的累计奖励。
- critic/returns/max / critic/returns/min: 回报的最大值 / 最小值。
- critic/values/mean: 价值函数(Value Function)估计的均值。反映了模型对某个状态未来总奖励的估计。
- critic/values/max / critic/values/min: 价值函数的最大值 / 最小值。
- tokens/response_length/mean: 生成响应的平均长度。
- tokens/response_length/max / tokens/response_length/min: 生成响应的最大长度 / 最小长度。
- tokens/prompt_length/mean: 提示的平均长度。
- tokens/prompt_length/max / tokens/prompt_length/min: 提示的最大长度 / 最小长度。
策略相关
- actor/lr: 当前策略网络(Actor)的学习率。学习率是优化器更新模型参数的步长。
- actor/ppo_ratio_high_clipfrac: PPO 策略优化时的高裁剪比例。
- actor/ppo_ratio_low_clipfrac: PPO 策略优化时的低裁剪比例。
- actor/ppo_ratio_clipfrac: PPO 策略优化时的裁剪比例。
- actor/ratio_mean: 策略网络(Actor)的平均 ratio (新旧策略对数概率之比的指数) 。
- actor/ratio_max / actor/ratio_min: 策略网络(Actor)的 ratio 的最大值 / 最小值。
- actor/clipfrac: 策略网络(Actor)的裁剪比例。
- actor/kl_loss: 当前策略与参考策略之间的KL散度惩罚项。用于防止策略偏离原始模型太远。
- actor/total_loss: 策略梯度损失、KL散度损失和熵损失(如果存在)的加权和。这是实际用于模型反向传播的损失。
- actor/approxkl: 当前策略与旧策略之间的近似KL散度。衡量每一步策略更新的步长。
- actor/policykl: 当前策略与旧策略之间的精确KL散度。
评估指标
- critic/ref_log_prob/mean: 参考模型输出的平均 log 概率。用于衡量旧策略或参考策略的性能基准。
- critic/old_log_prob/mean: 旧策略(训练前 Actor)输出的平均 log 概率。用于衡量新旧策略之间的差异。
- critic/entropy/mean: 策略的平均熵。熵衡量策略的随机性或探索性,高熵表示更强的探索。
- critic/reward_clip_frac: 奖励裁剪的比例。反映有多少奖励值被裁剪了,如果太高可能需要调整奖励范围或裁剪阈值。
PPO 损失指标
- actor/pg_loss: PPO算法的策略梯度损失。目标是最小化这个损失以改进策略。
- actor/weighted_pg_loss: 策略梯度损失加权后的值。
- actor/valid_samples: 当前批次中的有效样本数量。
- actor/total_samples: 当前批次中的总样本数量(即批次大小)。
- actor/valid_sample_ratio: 当前批次中的有效样本比例。
- actor/sample_weights_mean: 批次中所有样本权重的平均值。
- actor/sample_weights_min / actor/sample_weights_max: 批次中所有样本权重的最小值 / 最大值。
SFT 损失指标
- actor/sft_loss: 监督微调损失。
- actor/positive_sft_loss: 正样本监督微调损失。
- actor/negative_sft_loss: 负样本监督微调损失。
框架性能指标
全局系统指标
- system/tps: 每秒处理的 tokens 数量(Tokens Per Second)。这是衡量整个系统吞吐量的关键指标。
- system/samples: 已经处理的总样本数。
阶段耗时指标
- time/rollout: 数据收集 (Rollout) 阶段的耗时。
- time/ref_log_probs_values_reward: 计算参考模型 log 概率和价值的耗时。
- time/old_log_probs_values: 计算旧策略 log 概率和价值的耗时。
- time/adv: 优势(Advantages)计算阶段的耗时。
各执行阶段
在下面的时间指标和内存指标中,{metric_infix} 会被替换为具体的执行阶段标识,例如:
- train_step: 训练阶段
- generate: 文本生成/推理阶段
- model_update: 模型参数更新/同步阶段
- compute_log_probs: 计算对数概率阶段
- do_checkpoint: 模型保存/检查点阶段
- compute_values: 计算价值阶段
- compute_rewards: 计算奖励阶段
时间指标
- time/{metric_infix}/total: 整个操作的总执行时间(从进入 state_offload_manger 到退出)。
- time/{metric_infix}/execute: 实际业务逻辑(即 yield 部分,如模型训练、生成等)的执行时间。
- time/{metric_infix}/onload: 模型状态加载(strategy.load_states())到 GPU 或内存中的时间。
- time/{metric_infix}/offload: 模型状态从 GPU 或内存中卸载(strategy.offload_states())的时间。
GPU内存指标
- 开始时(模型状态卸载后)的内存快照
- memory/{metric_infix}/start/offload/allocated/{device_id}: 某个 device_id 上当前已分配的 GPU 内存量。
- memory/{metric_infix}/start/offload/reserved/{device_id}: 某个 device_id 上当前已预留的 GPU 内存量。
- memory/{metric_infix}/start/offload/max_allocated/{device_id}: 某个 device_id 上从本次操作开始到当前时刻,已分配的 GPU 内存的峰值。
- memory/{metric_infix}/start/offload/max_reserved/{device_id}: 某个 device_id 上从本次操作开始到当前时刻,已预留的 GPU 内存的峰值。
- 加载模型状态后(业务逻辑执行前)的内存快照
- memory/{metric_infix}/start/onload/allocated/{device_id}: 某个 device_id 上当前已分配的 GPU 内存量。
- memory/{metric_infix}/start/onload/reserved/{device_id}: 某个 device_id 上当前已预留的 GPU 内存量。
- memory/{metric_infix}/start/onload/max_allocated/{device_id}: 某个 device_id 上从本次操作开始到当前时刻,已分配的 GPU 内存的峰值。
- memory/{metric_infix}/start/onload/max_reserved/{device_id}: 某个 device_id 上从本次操作开始到当前时刻,已预留的 GPU 内存的峰值。
- 业务逻辑执行后(模型状态卸载前)的内存快照
- memory/{metric_infix}/end/onload/allocated/{device_id}: 某个 device_id 上当前已分配的 GPU 内存量。
- memory/{metric_infix}/end/onload/reserved/{device_id}: 某个 device_id 上当前已预留的 GPU 内存量。
- memory/{metric_infix}/end/onload/max_allocated/{device_id}: 某个 device_id 上从本次操作开始到当前时刻,已分配的 GPU 内存的峰值。
- memory/{metric_infix}/end/onload/max_reserved/{device_id}: 某个 device_id 上从本次操作开始到当前时刻,已预留的 GPU 内存的峰值。
- memory/{metric_infix}/end/onload/max_allocated_frac/{device_id}: 某个 device_id 上已分配 GPU 内存峰值占总 GPU 内存的比例 (分数)。
- memory/{metric_infix}/end/onload/max_reserved_frac/{device_id}: 某个 device_id 上已预留 GPU 内存峰值占总 GPU 内存的比例 (分数)。
- 卸载模型状态后(操作结束)的内存快照
- memory/{metric_infix}/end/offload/allocated/{device_id}: 某个 device_id 上当前已分配的 GPU 内存量。
- memory/{metric_infix}/end/offload/reserved/{device_id}: 某个 device_id 上当前已预留的 GPU 内存量。
- memory/{metric_infix}/end/offload/max_allocated/{device_id}: 某个 device_id 上从本次操作开始到当前时刻,已分配的 GPU 内存的峰值。
- memory/{metric_infix}/end/offload/max_reserved/{device_id}: 某个 device_id 上从本次操作开始到当前时刻,已预留的 GPU 内存的峰值。
CPU内存指标
- memory/cpu/{metric_infix}/start/rss: 进程在操作开始时占用的实际物理内存 (Resident Set Size)。
- memory/cpu/{metric_infix}/start/vms: 进程在操作开始时占用的虚拟内存 (Virtual Memory Size)。
- memory/cpu/{metric_infix}/end/rss: 进程在操作结束时占用的实际物理内存。
- memory/cpu/{metric_infix}/end/vms: 进程在操作结束时占用的虚拟内存。