混合协程
有栈(Stackful)协程和无栈(Stackless)协程目前在业界均使用广泛,但是我们在业务实践中发现二者都有各自的缺点。无栈协程运行时,协程函数调用会涉及内存分配、异常处理以及参数拷贝,虽然编译器层面尽可能优化内存分配,但是参数构造等过程始终存在。当函数调用栈过深时,无栈协程与普通函数相比性能下降比较严重。另外无栈协程应用起来存在一定代码传染性。反观有栈协程(Stackful)没有传染性问题,性能也不会和函数调用深度有关,但它存在其他问题。二者对比各有优缺,这里简单列举一些我们比较关注的:
无栈协程(Lazy)
- 可实现同步阻塞编码,异步执行。
- 切换性能极高,协程挂起和恢复时不存在上下文保存和恢复。
- 适合高并发异步场景,因为几乎无切换代价,非常适合海量协程协同执行。
- 代码侵入性较高,涉及函数返回类型,co_await等关键字,依赖项目要用支持C++20协程编译器。
- 性能与调用栈深度相关。
有栈协程(Uthread)
- 可实现同步阻塞编码,异步执行。
- 无代码侵入性,不涉及异步IO访问地方代码无需任何修改。
- 不适合高并发场景,协程挂起恢复涉及当前调用栈的保存和恢复,频繁挂起恢复性能差。
- 性能与调用栈深度无关,都是普通C++函数调用。
示例
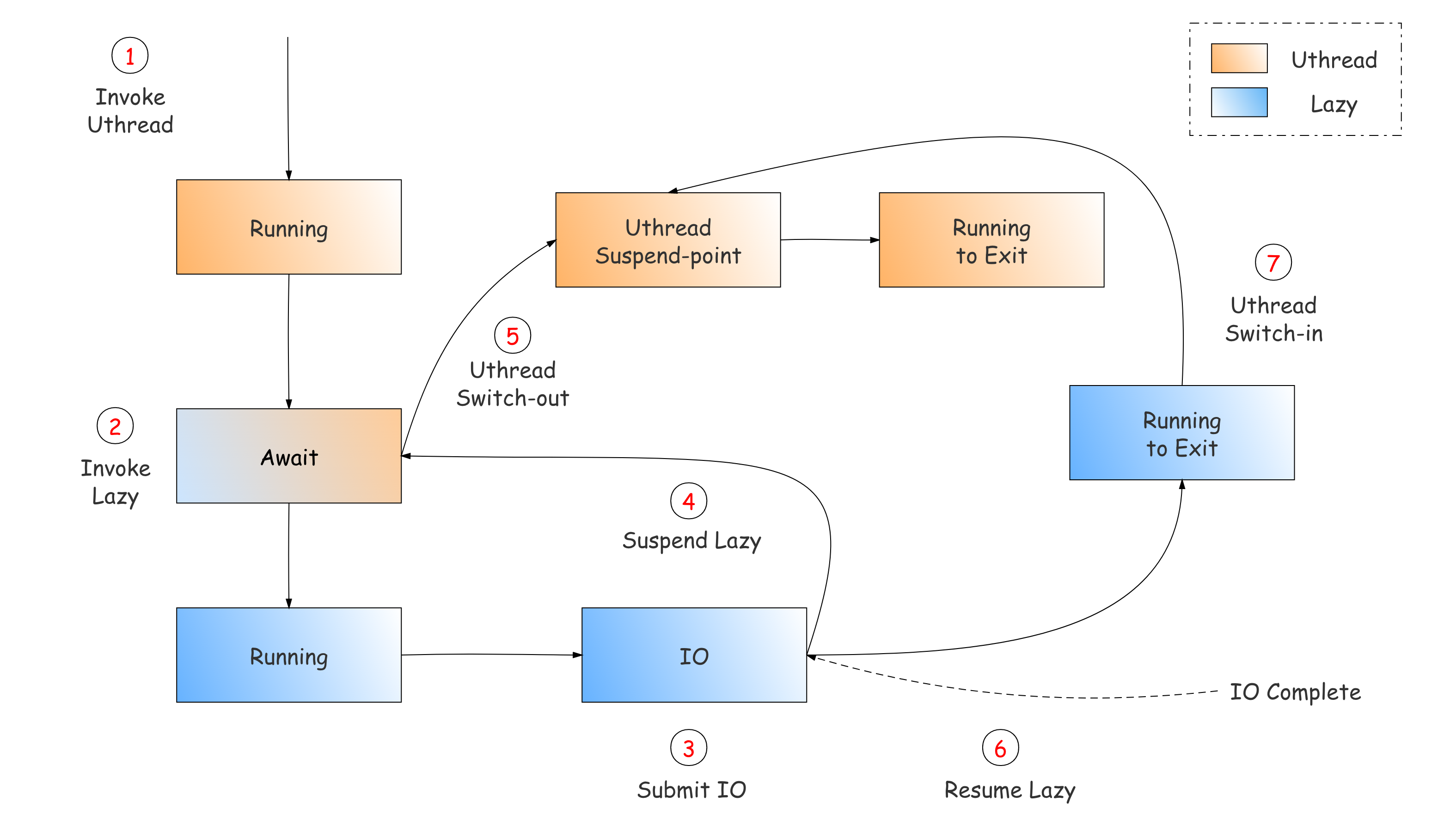
考虑到线上业务存在这样一个特点:用户请求会经过非常深的函数调用到达底层模块,在底层模块完成大量诸如文件IO访问等异步任务,完成后返回数据给上层继续处理,最终返回处理结果给用户。我们在实践中将用户请求放在有栈协程uthread中处理,在需要大量并发访问IO的底层模块采用无栈协程Lazy。这样一来,底层模块在做并行化IO查询时几乎没有切换开销,并且上游业务代码也无需代码改造就能实现全流程异步化。如下图所示。
总结
无栈协程相比有栈协程更适合海量协程协作式执行。由于侵入性,编译器版本等原因,想要业务全流程应用起来还是存在难度。考虑到有栈协程在一定程度能弥补这些劣势,在实践中我们提出了混合协程(Hybrid Coroutine)。混合协程允许代码在同一个请求会话中既可以跑在有栈协程上下文,也可以同时跑在无栈协程上下文中,极大释放各自优点,提高整体性能。