Experiment Data Analysis and Visualization
Experiment Data Tracking
The pipeline's configuration file supports two methods for data tracking:
- TensorBoard
- Weights & Biases (wandb)
# wandb (Weights & Biases) offers more advanced cloud-based experiment management and collaboration features.
#track_with: wandb
#tracker_kwargs:
# api_key:
# project: roll-agentic
# name: ${exp_name}_frozen_lake
# notes: "agentic_pipeline"
# tags:
# - agentic
# - roll
# - baseline
track_with: tensorboard
tracker_kwargs:
# log_dir is the root directory for TensorBoard log files. Each experiment run will create a timestamped subdirectory here.
log_dir: /data/oss_bucket_0/yali/llm/tensorboard/roll_exp/agentic_sokoban
Experiment Data Visualization
The following section uses TensorBoard as an example to illustrate how to visualize experiment data.
- Ensure TensorBoard is installed.
pip install tensorboard
- Launch TensorBoard. After the pipeline run completes, locate the timestamped directories for your experiment runs under the log_dir specified in the configuration (e.g., /data/oss_bucket_0/yali/llm/tensorboard/roll_exp/agentic_sokoban). Launch TensorBoard using the following command; it will scan this timestamped directory for your run logs:
tensorboard --logdir /data/oss_bucket_0/yali/llm/tensorboard/roll_exp/agentic_sokoban/{latest_date}
In the terminal, you will see a prompt similar to the one below:

Open localhost:6006 in your browser to view the TensorBoard interface. If you are using it on a remote machine, ensure that port forwarding is correctly configured.
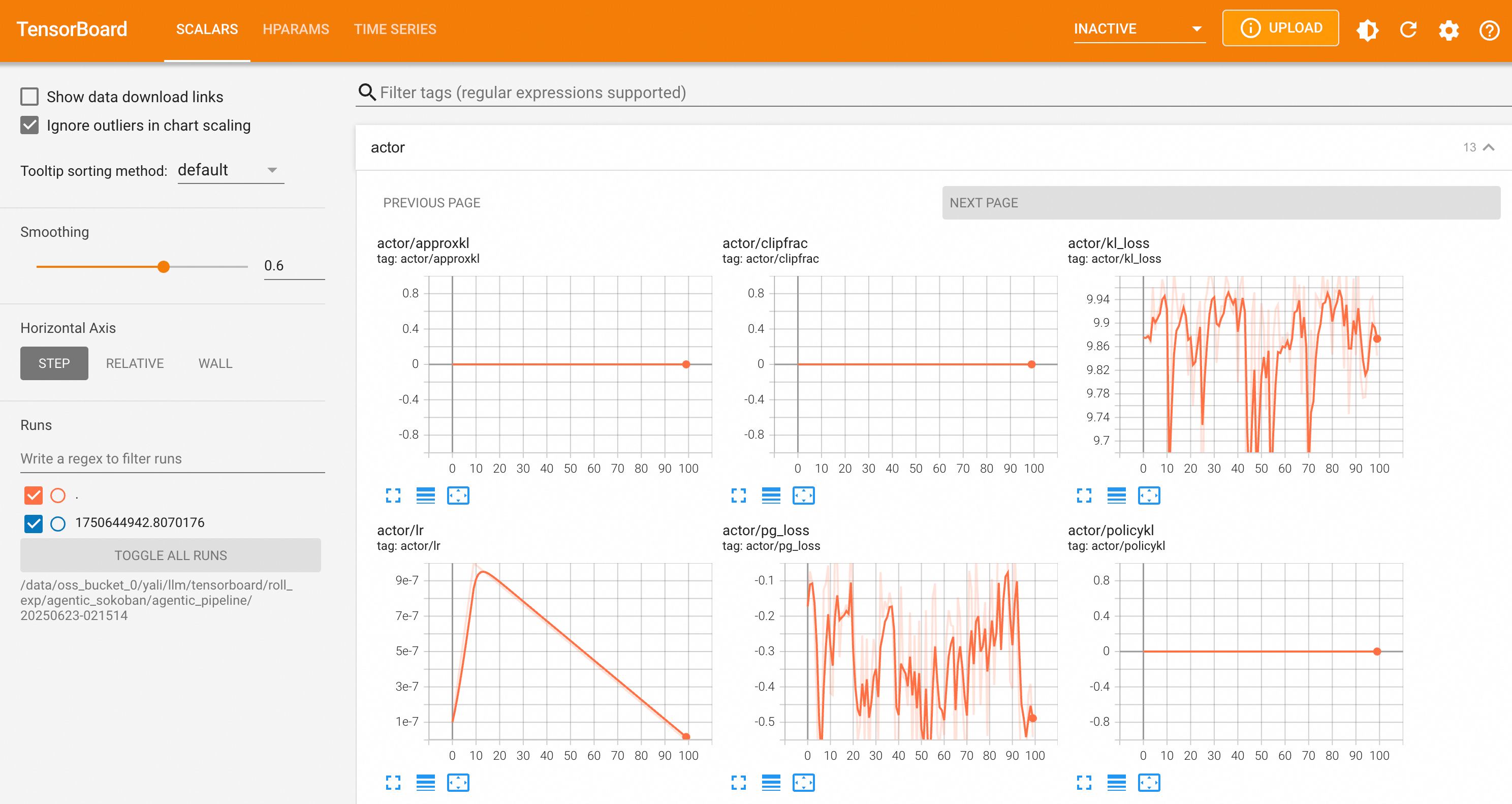
Algorithm Performance Metrics
Validation Phase
- val/score/mean: The average score per episode during the validation phase. Reflects the model's average performance on unseen environments.
- val/score/max / val/score/min: The maximum / minimum score per episode during the validation phase.
Value-related
- critic/lr: The learning rate of the value function (Critic). The learning rate determines the step size for updating model parameters by the optimizer.
- critic/loss: The loss between the value network's predicted value and the true return.
- critic/value: The mean of predicted values for states in the batch by the value network of the old policy (or behavior policy) at the beginning of the current PPO iteration, during data collection or training. These values typically serve as a baseline when calculating advantage functions.
- critic/vpred: The mean of predicted values for states in the batch by the currently optimizing value network. This value updates with each training iteration.
- critic/clipfrac: The fraction of values that were clipped due to value_clip in the value function.
- critic/error: The mean squared error between the value network's predicted value and the true return.
Reward-related
- critic/score/mean: The mean of the raw environmental rewards.
- critic/score/max / critic/score/min: The maximum / minimum of the raw environmental rewards.
- critic/rewards/mean: The mean of normalized/clipped rewards.
- critic/rewards/max / critic/rewards/min: The maximum / minimum of normalized/clipped rewards.
- critic/advantages/mean: The mean of Advantages. Reflects how much additional reward an action taken in a given state can yield compared to the average.
- critic/advantages/max / critic/advantages/min: The maximum / minimum of Advantages.
- critic/returns/mean: The mean of Returns. The expected cumulative reward.
- critic/returns/max / critic/returns/min: he maximum / minimum of Returns.
- critic/values/mean: The mean of Value Function estimates. Reflects the model's estimation of the total future reward for a given state.
- critic/values/max / critic/values/min: The maximum / minimum of Value Function estimates.
- tokens/response_length/mean: The average length of generated responses.
- tokens/response_length/max / tokens/response_length/min: The maximum / minimum length of generated responses.
- tokens/prompt_length/mean: The average length of prompts.
- tokens/prompt_length/max / tokens/prompt_length/min: The maximum / minimum length of prompts.
Policy-related
- actor/lr: The learning rate of the current policy network (Actor). The learning rate determines the step size for updating model parameters by the optimizer.
- actor/ppo_ratio_high_clipfrac: The high clipping fraction during PPO policy optimization.
- actor/ppo_ratio_low_clipfrac: The low clipping fraction during PPO policy optimization.
- actor/ppo_ratio_clipfrac: The clipping fraction during PPO policy optimization.
- actor/ratio_mean: The average ratio of the policy network (Actor) (exponent of the ratio of new to old policy log probabilities).
- actor/ratio_max / actor/ratio_min: The maximum / minimum of the policy network (Actor)'s ratio.
- actor/clipfrac: The clipping fraction of the policy network (Actor).
- actor/kl_loss: The KL divergence penalty term between the current policy and the reference policy. Used to prevent the policy from deviating too far from the original model.
- actor/total_loss: The weighted sum of policy gradient loss, KL divergence loss, and entropy loss (if present). This is the loss actually used for backpropagation of the model.
- actor/approxkl: The approximate KL divergence between the current policy and the old policy. Measures the step size of each policy update.
- actor/policykl: The exact KL divergence between the current policy and the old policy.
Evaluation Metrics
- critic/ref_log_prob/mean: The average log probability output by the reference model. Used to measure the performance baseline of the old or reference policy.
- critic/old_log_prob/mean: The average log probability output by the old policy (Actor before training). Primarily used in the PPO algorithm to measure the difference between new and old policies.
- critic/entropy/mean: The average entropy of the policy. Entropy measures the randomness or explorativeness of the policy; higher entropy indicates stronger exploration.
- critic/reward_clip_frac: The fraction of rewards that were clipped. Indicates how many reward values were clipped; if too high, it might require adjusting the reward range or clipping threshold.
PPO Loss Metrics
- actor/pg_loss: The policy gradient loss in the PPO algorithm. The goal is to minimize this loss to improve the policy.
- actor/weighted_pg_loss: The weighted value of the policy gradient loss.
- actor/valid_samples: The number of valid samples in the current batch.
- actor/total_samples: The total number of samples in the current batch (i.e., batch size).
- actor/valid_sample_ratio: The ratio of valid samples in the current batch.
- actor/sample_weights_mean: The average value of all sample weights in the batch.
- actor/sample_weights_min / actor/sample_weights_max: The minimum / maximum value of all sample weights in the batch.
SFT Loss Metrics
- actor/sft_loss: Supervised Fine-Tuning loss.
- actor/positive_sft_loss: Positive sample Supervised Fine-Tuning loss.
- actor/negative_sft_loss: Negative sample Supervised Fine-Tuning loss.
Framework Performance Metrics
Global System Metrics
- system/tps: Tokens Per Second. This is a key metric to measure the overall system throughput.
- system/samples: The total number of samples processed.
Phase Latency Metrics
- time/rollout: Latency of the Data Collection (Rollout) phase.
- time/ref_log_probs_values_reward: Latency for calculating reference model log probabilities and values.
- time/old_log_probs_values: Latency for calculating old policy log probabilities and values.
- time/adv: Latency of the Advantages Calculation phase.
Execution Phases
In the following time and memory metrics, {metric_infix} will be replaced by a specific execution phase identifier, for example:
- train_step: Training phase
- generate: Text generation/inference phase
- model_update: Model parameter update/synchronization phase
- compute_log_probs: Log probabilities computation phase
- do_checkpoint: Model saving/checkpointing phase
- compute_values: Values computation phase
- compute_rewards: Rewards computation phase
Time Metrics
- time/{metric_infix}/total: Total execution time of the entire operation (from entering state_offload_manager to exiting).
- time/{metric_infix}/execute: Execution time of the actual business logic (i.e., the yield part, such as model training, generation, etc.).
- time/{metric_infix}/onload: Time taken to load model states (strategy.load_states()) to GPU or memory.
- time/{metric_infix}/offload: Time taken to offload model states (strategy.offload_states()) from GPU or memory.
GPU Memory Metrics
- Memory snapshot at start (after model state offload) (start/offload)
- memory/{metric_infix}/start/offload/allocated/{device_id}: Current allocated GPU memory on a specific device_id.
- memory/{metric_infix}/start/offload/reserved/{device_id}: Current reserved GPU memory on a specific device_id.
- memory/{metric_infix}/start/offload/max_allocated/{device_id}: Peak allocated GPU memory on a specific device_id from the start of this operation to the current moment.
- memory/{metric_infix}/start/offload/max_reserved/{device_id}: Peak reserved GPU memory on a specific device_id from the start of this operation to the current moment.
- Memory snapshot after model state load (before business logic execution) (start/onload)
- memory/{metric_infix}/start/onload/allocated/{device_id}: Current allocated GPU memory on a specific device_id.
- memory/{metric_infix}/start/onload/reserved/{device_id}: Current reserved GPU memory on a specific device_id.
- memory/{metric_infix}/start/onload/max_allocated/{device_id}: Peak allocated GPU memory on a specific device_id from the start of this operation to the current moment.
- memory/{metric_infix}/start/onload/max_reserved/{device_id}: Peak reserved GPU memory on a specific device_id from the start of this operation to the current moment.
- Memory snapshot after business logic execution (before model state offload) (end/onload)
- memory/{metric_infix}/end/onload/allocated/{device_id}: Current allocated GPU memory on a specific device_id.
- memory/{metric_infix}/end/onload/reserved/{device_id}: Current reserved GPU memory on a specific device_id.
- memory/{metric_infix}/end/onload/max_allocated/{device_id}: Peak allocated GPU memory on a specific device_id from the start of this operation to the current moment.
- memory/{metric_infix}/end/onload/max_reserved/{device_id}: Peak reserved GPU memory on a specific device_id from the start of this operation to the current moment.
- memory/{metric_infix}/end/onload/max_allocated_frac/{device_id}: Fraction of peak allocated GPU memory to total GPU memory on a specific device_id.
- memory/{metric_infix}/end/onload/max_reserved_frac/{device_id}: Fraction of peak reserved GPU memory to total GPU memory on a specific device_id.
- Memory snapshot after model state offload (after operation completion) (end/offload)
- memory/{metric_infix}/end/offload/allocated/{device_id}: Current allocated GPU memory on a specific device_id.
- memory/{metric_infix}/end/offload/reserved/{device_id}: Current reserved GPU memory on a specific device_id.
- memory/{metric_infix}/end/offload/max_allocated/{device_id}: Peak allocated GPU memory on a specific device_id from the start of this operation to the current moment.
- memory/{metric_infix}/end/offload/max_reserved/{device_id}: Peak reserved GPU memory on a specific device_id from the start of this operation to the current moment.
CPU Memory Metrics
- memory/cpu/{metric_infix}/start/rss: Resident Set Size (actual physical memory used by the process) at the start of the operation.
- memory/cpu/{metric_infix}/start/vms: Virtual Memory Size (virtual memory used by the process) at the start of the operation.
- memory/cpu/{metric_infix}/end/rss: Resident Set Size (actual physical memory used by the process) at the end of the operation.
- memory/cpu/{metric_infix}/end/vms: Virtual Memory Size (virtual memory used by the process) at the end of the operation.