struct_pack简介
struct_pack是一个以零成本抽象,高度易用为特色序列化库。通常情况下只需一行代码即可完成复杂结构体的序列化/反序列化。对于聚合类型,用户无需定义任何DSL,宏或模板代码。struct_pack也支持使用宏来自定义非聚合类型的反射。struct_pack可通过编译期反射自动支持对C++结构体的序列化。其综合性能比protobuf,msgpack大幅提升(详细可以看benchmark部分)。
下面,我们以一个简单的对象为例展示struc_pack的基本用法。
struct person {
int64_t id;
std::string name;
int age;
double salary;
};
person person1{.id = 1, .name = "hello struct pack", .age = 20, .salary = 1024.42};序列化
基本用法
// 1行代码序列化
std::vector<char> result = struct_pack::serialize(person1);指定序列化返回的容器类型
auto result = struct_pack::serialize<std::string>(person1);
//指定使用std::string而不是std::vector<char>将序列化结果保存到已有的容器尾部
std::string result="The next line is struct_pack serialize result.\n";
auto result = struct_pack::serialize_to(result,person1);
//将结果保存到已有的容器尾部。将序列化结果保存到指针指向的内存中。
auto sz=struct_pack::get_needed_siarray(person1);
std::unique_ptr array=std::make_unique<char[]>(sz);
auto result = struct_pack::serialize_to(array.get(),sz,person1);
//将结果保存指针指向的内存中。多参数序列化
auto result=struct_pack::serialize(person1.id, person1.name, person1.age, person1.salary);
//serialize as std::tuple<int64_t, std::string, int, double>将序列化结果保存到输出流
std::ofstream writer("struct_pack_demo.data",
std::ofstream::out | std::ofstream::binary);
struct_pack::serialize_to(writer, person1);反序列化
基本用法
// 1行代码反序列化
auto person2 = deserialize<person>(buffer);
assert(person2); // person2.has_value() == true
assert(person2.value()==person1);从指针指向的内存中反序列化
// 从指针指向的内存中反序列化
auto person2 = deserialize<person>(buffer.data(),buffer.size());
assert(person2); //person2.has_value() == true
assert(person2.value()==person1);反序列化(将结果保存到已有的对象中)
// 将结果保存到已有的对象中
person person2;
auto ec = deserialize_to(person2, buffer);
assert(!ec); // no error
assert(person2==person1);多参数反序列化
auto person2 = deserialize<int64_t,std::string,int,double>(buffer);
assert(person2); // person2.has_value() == true
auto &&[id,name,age,salary]=person2.value();
assert(person1.id==id);
assert(person1.name==name);
assert(person1.age==age);
assert(person1.salary==salary);从输入流中反序列化
std::ifstream ifs("struct_pack_demo.data",
std::ofstream::in | std::ofstream::binary);
auto person2 = struct_pack::deserialize<person>(ifs);
assert(person2 == person1);部分反序列化
有时候只想反序列化对象的某个特定的字段而不是全部,这时候就可以用部分反序列化功能了,这样可以避免全部反序列化,大幅提升效率。
// 只反序列化person的第2个字段
auto name = get_field<person, 1>(buffer.data(), buffer.size());
assert(name); // name.has_value() == true
assert(name.value() == "hello struct pack");支持序列化所有的STL容器、自定义容器和optional
含各种容器的对象序列化
enum class Color { red, black, white };
struct complicated_object {
Color color;
int a;
std::string b;
std::vector<person> c;
std::list<std::string> d;
std::deque<int> e;
std::map<int, person> f;
std::multimap<int, person> g;
std::set<std::string> h;
std::multiset<int> i;
std::unordered_map<int, person> j;
std::unordered_multimap<int, int> k;
std::array<person, 2> m;
person n[2];
std::pair<std::string, person> o;
std::optional<int> p;
std::unique_ptr<int> q;
};
struct nested_object {
int id;
std::string name;
person p;
complicated_object o;
};
nested_object nested{.id = 2, .name = "tom", .p = {20, "tom"}, .o = {}};
auto buffer = serialize(nested);
auto nested2 = deserialize(buffer.data(), buffer.size());
assert(nested2)
assert(nested2==nested1);对整数启用变长压缩编码
struct rect {
int a,b,c,d;
constexpr static auto struct_pack_config = struct_pack::ENCODING_WITH_VARINT| struct_pack::USE_FAST_VARINT;
};自定义功能支持
用户自定义反射
有时候用户需要支持非聚合的结构体,或者自定义各字段序列化的顺序,这些可以通过宏函数YLT_REFL(typename, fieldname1, fieldname2 ...)来支持。
namespace test {
class person : std::vector<int> {
private:
std::string mess;
public:
int age;
std::string name;
auto operator==(const person& rhs) const {
return age == rhs.age && name == rhs.name;
}
person() = default;
person(int age, const std::string& name) : age(age), name(name) {}
};
YLT_REFL(person, name, age);
}YLT_REFL(typename, fieldname1, fieldname2 ...)填入的第一个参数是需要反射的类型名,随后是若干个字段名,代表反射信息的各个字段。 该宏必须定义在反射的类型所在的命名空间中。 如果该类型不具有默认构造函数,则无法使用函数struct_pack::deserialize,不过你依然可以使用struct_pack::deserialize_to来实现反序列化。 它使得struct_pack可以支持那些非聚合的结构体类型,允许用户自定义构造函数,继承其他类型,添加不序列化的字段等等。
有时,用户需要序列化/反序列化那些private字段,此时我们只需要在结构体内定义宏YLT_REFL(typename, fieldname1, fieldname2 ...)就行了。
namespace example2 {
class person {
private:
int age;
std::string name;
public:
auto operator==(const person& rhs) const {
return age == rhs.age && name == rhs.name;
}
person() = default;
person(int age, const std::string& name) : age(age), name(name) {}
YLT_REFL(person, age, name);
};
} // namespace example2该宏必须声明在结构体内部,其原理是在类内生成反射相关的静态函数。
用户甚至可以在YLT_REFL中,将返回左值引用的成员函数注册为结构体的字段,这极大的扩展了struct_pack的灵活性。
namespace example3 {
class person {
private:
int age_;
std::string name_;
public:
auto operator==(const person& rhs) const {
return age_ == rhs.age_ && name_ == rhs.name_;
}
person() = default;
person(int age, const std::string& name) : age_(age), name_(name) {}
int& age() { return age_; };
const int& age() const { return age_; };
std::string& name() { return name_; };
const std::string& name() const { return name_; };
};
YLT_REFL(person, age(), name());
} // namespace example3
注册的成员函数必须返回一个引用,并且该函数具有常量和非常量的重载。自定义类型的序列化
struct_pack支持序列化自定义类型。
该类型可以被抽象为类型系统中已有的类型
例如,假如我们需要序列化一个第三方库的map类型(absl , boost...):我们只需要保证其符合struct_pack类型系统中对于map的约束即可。
// We should not inherit from stl container, this case just for testing.
template <typename Key, typename Value>
struct my_map : public std::map<Key, Value> {};
my_map<int, std::string> map1;
map1.emplace(1, "tom");
map1.emplace(2, "jerry");
absl::flat_hash_map<int, std::string> map2 =
{{1, "huey"}, {2, "dewey"}, {3, "louie"},};
auto buffer1 = serialize(map1);
auto buffer2 = serialize(map2);关于自定义类型的更多细节,请见:
该类型不能被抽象为类型系统中已有的类型
此时,我们也支持自定义的序列化,用户只需要自定义以下三个函数即可:
- sp_get_needed_size
- sp_serialize_to
- sp_deserialize_to
例如,下面是一个支持自定义二维数组类型的序列化/反序列化的例子。
struct array2D {
unsigned int x;
unsigned int y;
float* p;
array2D(unsigned int x, unsigned int y) : x(x), y(y) {
p = (float*)calloc(1ull * x * y, sizeof(float));
}
array2D(const array2D&) = delete;
array2D(array2D&& o) : x(o.x), y(o.y), p(o.p) { o.p = nullptr; };
array2D& operator=(const array2D&) = delete;
array2D& operator=(array2D&& o) {
x = o.x;
y = o.y;
p = o.p;
o.p = nullptr;
return *this;
}
float& operator()(std::size_t i, std::size_t j) { return p[i * y + j]; }
bool operator==(const array2D& o) const {
return x == o.x && y == o.y &&
memcmp(p, o.p, 1ull * x * y * sizeof(float)) == 0;
}
array2D() : x(0), y(0), p(nullptr) {}
~array2D() { free(p); }
};
// 你需要自定义以下函数
// 1. sp_get_needed_size: 预计算序列化长度
std::size_t sp_get_needed_size(const array2D& ar) {
return 2 * struct_pack::get_write_size(ar.x) +
struct_pack::get_write_size(ar.p, 1ull * ar.x * ar.y);
}
// 2. sp_serialize_to: 将对象序列化到writer
template </*struct_pack::writer_t*/ typename Writer>
void sp_serialize_to(Writer& writer, const array2D& ar) {
struct_pack::write(writer, ar.x);
struct_pack::write(writer, ar.y);
struct_pack::write(writer, ar.p, 1ull * ar.x * ar.y);
}
// 3. sp_deserialize_to: 从reader反序列化对象
template </*struct_pack::reader_t*/ typename Reader>
struct_pack::err_code sp_deserialize_to(Reader& reader, array2D& ar) {
if (auto ec = struct_pack::read(reader, ar.x); ec) {
return ec;
}
if (auto ec = struct_pack::read(reader, ar.y); ec) {
return ec;
}
auto length = 1ull * ar.x * ar.y * sizeof(float);
if constexpr (struct_pack::checkable_reader_t<Reader>) {
if (!reader.check(length)) {
//checkable_reader_t允许我们在读取数据前先检查是否超出长度限制
return struct_pack::errc::no_buffer_space;
}
}
ar.p = (float*)malloc(length);
auto ec = struct_pack::read(reader, ar.p, 1ull * ar.x * ar.y);
if (ec) {
free(ar.p);
}
return ec;
// 4. 默认用于类型检查的字符串就是该类型的名字. 你也可以通过下面的函数来配置
// constexpr std::string_view sp_set_type_name(test*) { return "myarray2D"; }
// 5. 如果你想使用 struct_pack::get_field/struct_pack::get_field_to, 还需要定义下面的函数以跳过自定义类型的反序列化。
// template <typename Reader>
// struct_pack::err_code sp_deserialize_to_with_skip(Reader& reader, array2D& ar);
}
void user_defined_serialization() {
std::vector<my_name_space::array2D> ar;
ar.emplace_back(11, 22);
ar.emplace_back(114, 514);
ar[0](1, 6) = 3.14;
ar[1](87, 111) = 2.71;
auto buffer = struct_pack::serialize(ar);
auto result = struct_pack::deserialize<decltype(ar)>(buffer);
assert(result.has_value());
assert(ar == result);
}序列化到自定义的输出流
该流需要满足以下约束条件:
template <typename T>
concept writer_t = requires(T t) {
t.write((const char *)nullptr, std::size_t{}); //向流输出一段数据。返回值应能隐式转换为bool值,出错时应返回false。
};例如:
//一个简单的输出流,对fwrite函数进行封装。
struct fwrite_stream {
FILE* file;
bool write(const char* data, std::size_t sz) {
return fwrite(data, sz, 1, file) == 1;
}
fwrite_stream(const char* file_name) : file(fopen(file_name, "wb")) {}
~fwrite_stream() { fclose(file); }
};
// ...
fwrite_stream writer("struct_pack_demo.data");
struct_pack::serialize_to(writer, person);从自定义的输入流中反序列化
该流需要满足以下约束条件:
template <typename T>
concept reader_t = requires(T t) {
t.read((char *)nullptr, std::size_t{}); //从流中读取一段数据。返回值应能隐式转换为bool值,出错时应返回false。
t.ignore(std::size_t{}); //从流中跳过一段数据。返回值应能隐式转换为bool值,出错时应返回false。
t.tellg(); //返回一个无符号整数,代表当前的绝对读取位置
};此外,如果该流还额外支持read_view函数,则支持对string_view的零拷贝优化。
template <typename T>
concept view_reader_t = reader_t<T> && requires(T t) {
{ t.read_view(std::size_t{}) } -> std::convertible_to<const char *>;
//从流中读取一段视图(零拷贝读取),返回值为该视图指向的起始位置,出错时应返回空指针。
};示例代码如下所示:
//一个简单的输入流,对fread函数进行封装。
struct fread_stream {
FILE* file;
bool read(char* data, std::size_t sz) {
return fread(data, sz, 1, file) == 1;
}
bool ignore(std::size_t sz) { return fseek(file, sz, SEEK_CUR) == 0; }
std::size_t tellg() {
//if you worry about ftell performance, just use an variable to record it.
return ftell(file);
}
fread_stream(const char* file_name) : file(fopen(file_name, "rb")) {}
~fread_stream() { fclose(file); }
};
//...
fread_stream ifs("struct_pack_demo.data");
auto person2 = struct_pack::deserialize<person>(ifs);
assert(person2 == person);支持可变长编码:
{
std::vector<struct_pack::var_int32_t> vec={-1,0,1,2,3,4,5,6,7};
auto buffer = std::serialize(vec); //zigzag+varint编码
}
{
std::vector<struct_pack::var_uint64_t> vec={1,2,3,4,5,6,7,UINT64_MAX};
auto buffer = std::serialize(vec); //varint编码
}
struct rect {
int a,b,c,d;
constexpr static auto struct_pack_config = struct_pack::ENCODING_WITH_VARINT| struct_pack::USE_FAST_VARINT;
// 启用快速变长编码
};派生类型支持
struct_pack 同样支持序列化/反序列化派生自基类的子类,但需要额外的宏来标记派生关系并自动生成工厂函数。
// base
// / |
// obj1 obj2
// |
// obj3
struct base {
uint64_t ID;
virtual uint32_t get_struct_pack_id()
const = 0; // 必须在基类中声明该函数。
virtual ~base(){};
};
struct obj1 : public base {
std::string name;
virtual uint32_t get_struct_pack_id()
const override; // 必须在派生类中声明该函数。
};
YLT_REFL(obj1, ID, name);
struct obj2 : public base {
std::array<float, 5> data;
virtual uint32_t get_struct_pack_id() const override;
};
YLT_REFL(obj2, ID, data);
struct obj3 : public obj1 {
int age;
virtual uint32_t get_struct_pack_id() const override;
};
YLT_REFL(obj3, ID, name, age);
STRUCT_PACK_DERIVED_DECL(base, obj1, obj2, obj3);
// 声明基类和派生类之间的继承关系。
STRUCT_PACK_DERIVED_IMPL(base, obj1, obj2, obj3);
// 实现get_struct_pack_id函数。然后用户就可以正常的序列化/反序列化unique_ptr<base>类型了。
std::vector<std::unique_ptr<base>> data;
data.emplace_back(std::make_unique<obj2>());
data.emplace_back(std::make_unique<obj1>());
data.emplace_back(std::make_unique<obj3>());
auto ret = struct_pack::serialize(data);
auto result =
struct_pack::deserialize<std::vector<std::unique_ptr<base>>>(ret);
assert(result.has_value()); // check deserialize ok
assert(result->size() == 3); // check vector size用户同样可以序列化任意派生类然后将其反序列化为指向基类的指针。
auto ret = struct_pack::serialize(obj3{});
auto result =
struct_pack::deserialize_derived_class<base, obj1, obj2, obj3>(ret);
assert(result.has_value()); // check deserialize ok
std::unique_ptr<base> ptr = std::move(result.value());
assert(ptr != nullptr);ID冲突/哈希冲突
当两个派生类型具有完全相同的字段时,会发生ID冲突,因为struct_pack通过类型哈希来生成ID。两个相同的ID将导致struct_pack无法正确反序列化出对应的派生类。struct_pack会在编译期检查出这样的错误。
此外,任意两个不同的类型也有$2^-32$的概率发生哈希冲突,导致struct_pack无法利用哈希信息检查出类型错误。在Debug模式下,struct_pack默认带有完整类型字符串,以缓解哈希冲突。
用户可以手动给类型打标记来修复这一问题。即给该类型添加成员constexpr static std::size_t struct_pack_id并赋一个唯一的初值。如果不想侵入式的修改类的定义,也可以选择在同namespace下添加函数constexpr std::size_t struct_pack_id(Type*)。
struct obj1 {
std::string name;
virtual uint32_t get_struct_pack_id() const;
};
YLT_REFL(obj1, name);
struct obj2 : public obj1 {
virtual uint32_t get_struct_pack_id() const override;
constexpr static std::size_t struct_pack_id = 114514;
};
YLT_REFL(obj2, name);当添加了该字段/函数后,struct_pack会在类型字符串中加上该ID,从而保证两个类型之间具有不同的类型哈希值,从而解决ID冲突/哈希冲突。
benchmark
测试方法
待序列化的对象已经预先初始化,存储序列化结果的内存已经预先分配。对每个测试用例。我们运行一百万次序列化/反序列化,对结果取平均值。
测试对象
- 含有整形、浮点型和字符串类型person对象
struct person {
int64_t id;
std::string name;
int age;
double salary;
};- 含有十几个字段包括嵌套对象的复杂对象monster
enum Color : uint8_t { Red, Green, Blue };
struct Vec3 {
float x;
float y;
float z;
};
struct Weapon {
std::string name;
int16_t damage;
};
struct Monster {
Vec3 pos;
int16_t mana;
int16_t hp;
std::string name;
std::vector<uint8_t> inventory;
Color color;
std::vector<Weapon> weapons;
Weapon equipped;
std::vector<Vec3> path;
};- 含有4个int32的rect对象
struct rect {
int32_t x;
int32_t y;
int32_t width;
int32_t height;
};测试环境
Compiler: Alibaba Clang 13
CPU: (Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz)
测试结果
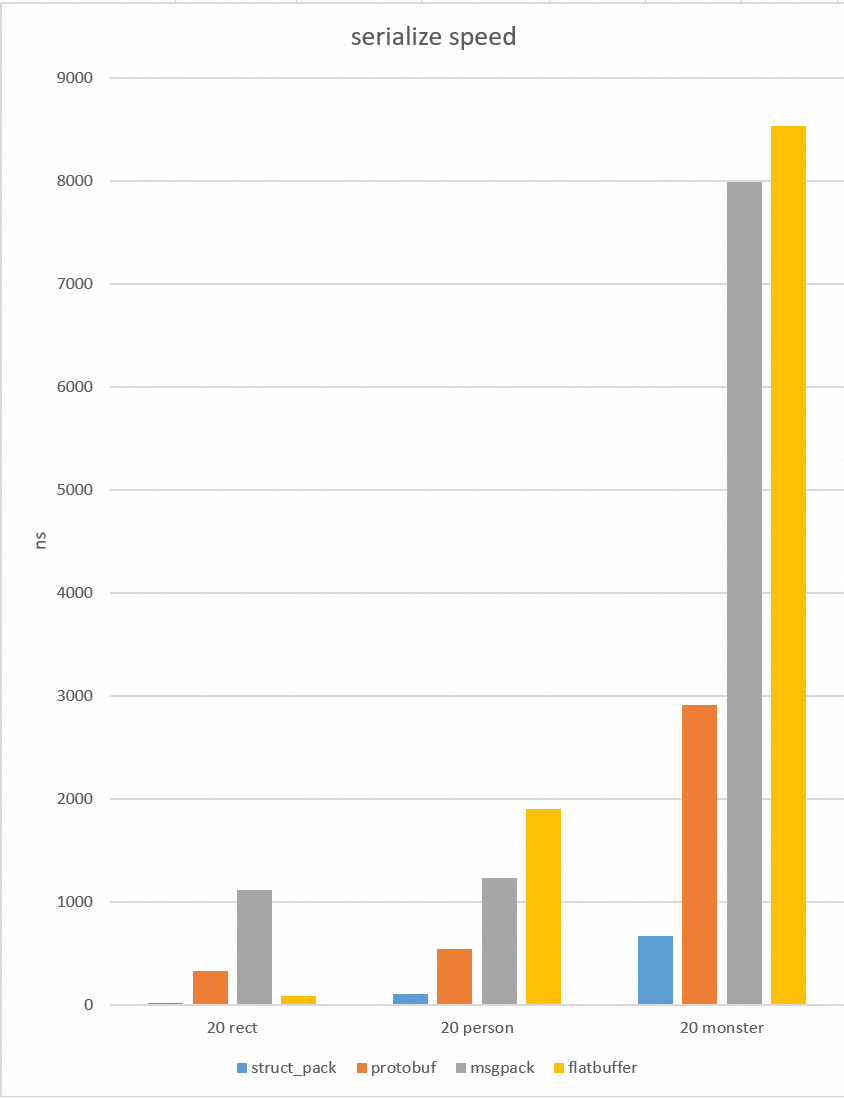
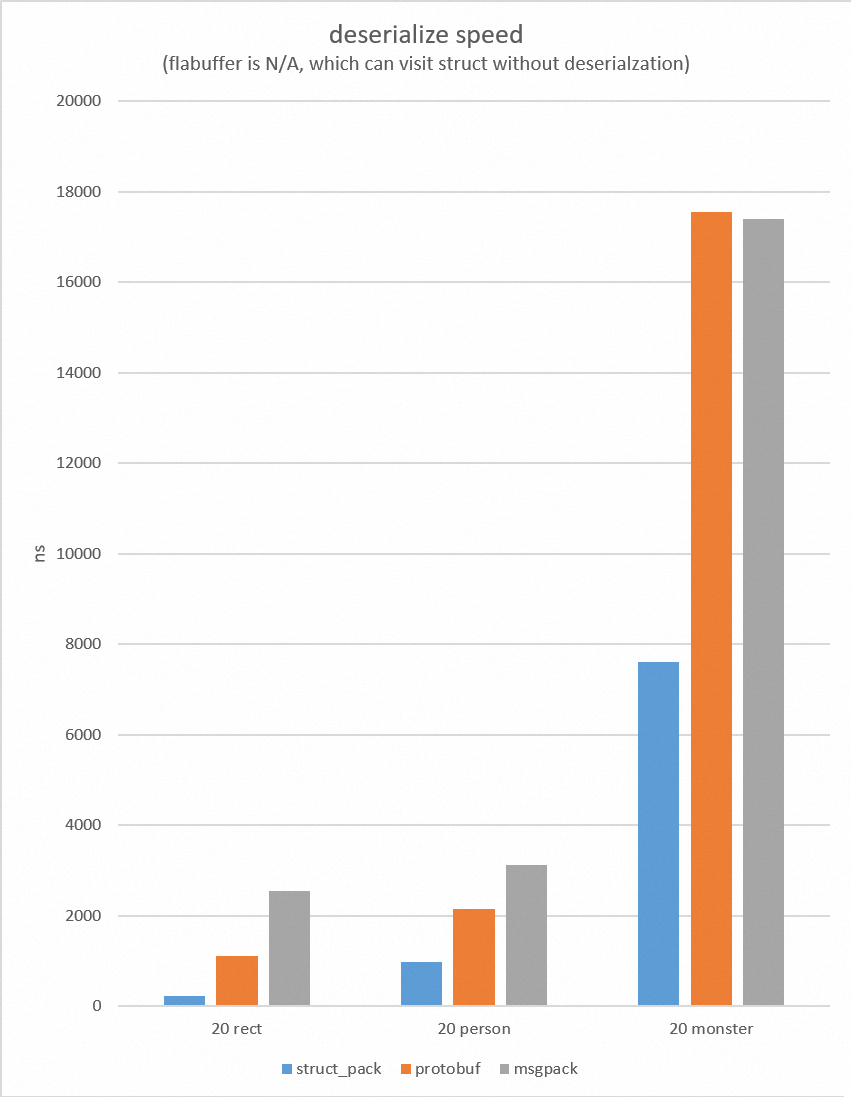
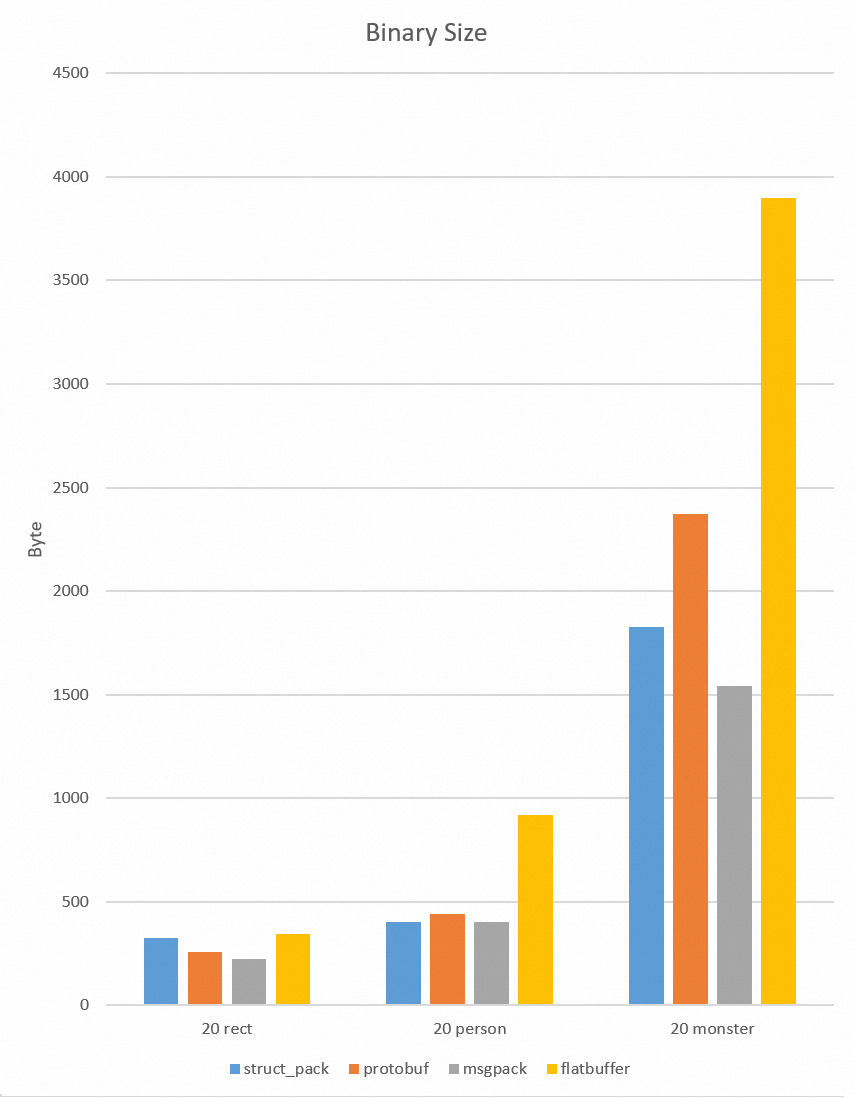
向前/向后兼容性
当对象增加新的字段时,怎么保证兼容新旧对象的解析呢?当用户需要添加字段时,只需要在 增加新的 struct_pack::compatible<T> 字段即可。
以person对象为例:
struct person {
int age;
std::string name;
};
struct person_v0 {
int age;
std::string name;
struct_pack::compatible<bool> maybe; //版本号默认为0
};
struct person_v1 {
int age;
std::string name;
struct_pack::compatible<int32_t,20230101> id; //版本号为20230101
struct_pack::compatible<bool> maybe;
struct_pack::compatible<std::string,20230101> password; //版本号为20230101
};
struct person_v2 {
int age;
std::string name;
struct_pack::compatible<int32_t,20230101> id;
struct_pack::compatible<bool> maybe;
struct_pack::compatible<std::string,20230101> password;
struct_pack::compatible<double,20230402> salary; //版本号应该递增。故新填入的版本号20230402大于20230101
};struct_pack保证上述的这四个类型之间,可以通过序列化和反序列化安全的相互转换到任何一个其他类型,从而实现了向前/向后的兼容性。
注意,如果版本号不递增,则struct_pack不能保证不同版本结构体之间的兼容性。由于struct_pack不检查compatible字段的类型,因此这种情况下的类型转换是未定义行为!
为什么struct_pack更快?
- 精简的类型信息,高效的类型校验。MD5计算在编译期完成,运行时只需要比较32bit的hash值是否相同即可。
- struct_pack是一个模板库,鼓励编译器积极的内联函数。
- 0成本抽象,不会为用不到的特性付出运行时代价。
- struct_pack的内存布局更接近于C++结构体原始的内存布局,减少了序列化反序列化的工作量。
- 编译期类型计算允许struct_pack根据不同的类型生成不同的代码。因此我们可以根据不同的类型的特点做优化。例如对于连续容器可以直接memcpy,对于string_view反序列化时可以采用零拷贝优化。